Paper https://research.cs.cornell.edu/projects/Quicksilver/public_pdfs/SWIM.pdf
Tại sao cần tìm hiểu
- Xem xét ứng dụng thực tiễn của Gossip protocol
- Được implement trong thư viện hashicorp/membership, là thư viện nền cho các thư viện lớn khác của Hashicorp (Consul; Nomad)
- Tài liệu khá tốt để tìm hiểu: Paper (SWIM + Lifeguard), implementation (hashicorp/membership), presentations, …
- Khi đọc sơ qua paper, có đi qua rất nhiều thuật ngữ đã tìm hiểu qua những course trước đó (e.g.: Failure detector; Virtual Synchrony; FLP theorem). Có thể là một paper tốt để có thể giới thiệu sơ về các khái niệm này.
Agenda
- Tổng quan về Asynchronous network và Failure Detector
- Group memberships protocol
- SWIM protocol
- Optional: xem xét implementation trong hashicorp/membership
Nguồn kiến thức
- EDX Distributed System Part 1
- Paper: SWIM: Scalable Weakly-consistent Infection-style Process Group Membership Protocol
- Paper: Lifeguard: Local Health Awareness for More Accurate Failure Detection
Failure Detector
2 thuộc tính quan trọng khi phân tích trong hệ thống distributed system
- Safety: nothing bad ever happens
- Liveness: Something good eventually happens.
Dựa vào đó, ta sẽ phân tích 2 thuộc tính trên ở Failure Detector:
Safety requirement: Completeness
Nói về thời điểm một crash node có thể được phát hiện bởi các node khác đang hoạt động trong hệ thống. Có 2 level về completeness:
- Strong completeness: every crashed process is eventually detected by all correct processes
- Weak completeness: every crashed process is eventually detected by some correct processes
Liveness requirement: Accuracy
Requirement này nói về các alive node, khi nào có thể đưa vào diện “tình nghi”. Có 4 level:
- Strong accuracy: không có process nào được đưa vào diện bị tình nghi trước khi bị crash.
- Weak accuracy: có một correct process không bao giờ bị tình nghi bởi các process khác.
- Eventual Strong accuracy: sau một khoảng thời gian hữu hạn, hệ thống trở về trạng thái strong accuracy
- Eventual Weak accuracy: sau một khoảng thời gian hữu hạn, hệ thống trở về trạng thái weak accuracy
Dựa vào cách chọn level cho completeness và accuracy, ta có thể phát triển những thuật toán khác nhau. Do scope của bài viết, ta sẽ không trình bày chi tiết ở đây.

https://en.wikipedia.org/wiki/Failure_detector
Asynchronous network
Asynchronous system
- Không có ràng buộc về điều kiện thời gian: Không có chặn trên cho thời gian gửi nhận / thời gian xử lí / đồng hồ trên mỗi máy tính trong mạng có thể khác nhau.
- Không có global clock. Không thể biết được total order của các event.
Tương quan giữa asynchronous network và fault tolerance
- Có thể đạt được completeness ? –> Có thể: Nghi ngờ hết mọi tiến trình hoạt động.
- Có thể đạt được accuracy ? –> Có thể: ngưng việc tình nghi các tiến trình hoạt động.
- Có thể đạt được cả completeness và accuracy ? -> Không thể.
We can’t have safety, liveness, full asynchrony, and fault tolerance all at the same time.
(FLP Theorem)
Failure detectors are feasible only in synchronous system and partially synchronous system.
Cộng đồng research đúc kết ra một số thuộc tính quan trọng khi đánh giá một thuận toán về failure detector:
- Strong completeness (liveness: crash bởi bất kì node nào sẽ được detect bởi tất cả các nodee đang healthy khác.
- Speed of failure detection (liveness): thời gian từ khi một node M_i bị crash cho đến khi được phát hiện bởi một - node khác trong hệ thống.
- Accuracy (safety): Tỉ lệ của false positive của detector.
- Network message load: bytes/second generated bởi protocol.
–> Ta sẽ phân tích các thuật toán dựa trên các thuật tính này.
Group Membership Protocol
Group Membership Protocol: tìm cách để truyền thông tin của các member trong mạng (joins / leave / failure).
Trong đấy, có bài toán quan trọng là failure detection. Failure detection có thể implement cơ bản bằng giao thức all-to-all heartbeat protocol
Thuật toán: đều đặn, các node gửi gói tin heartbeat đến toàn bộ các member khác trong group (kèm theo một counter). Một node M_i được đánh dấu là bị crash khi tồn tại một node M_j không nhận được gói tin từ M_i trong một khoảng thời gian.
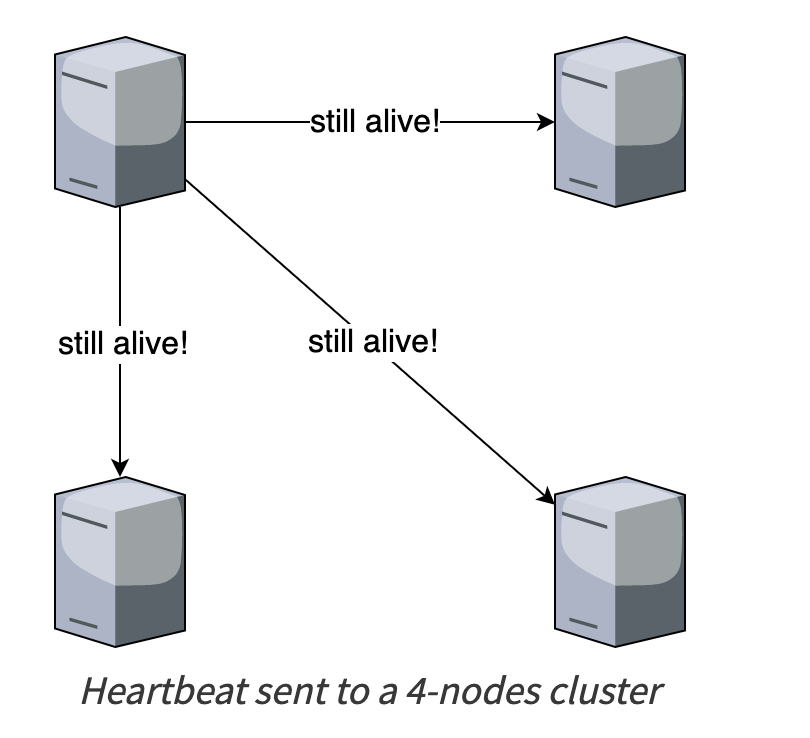
Đánh giá
- Strong completeness: Yes. Vì mỗi node đều gửi heartbeat đến mọi node khác. Khi có một node bị crash, thì chắc chắn toàn bộ các node còn lại đều phát hiện được.
- Speed of failure detection (liveness): gỉa sử timeout là T và số lần retry là R thì thời gian detect được failure là
R*T. - Accuracy (safety): Dựa vào công thức trên, ta có thể quyết định được trade-off: nếu limit được gán giá trị thấp, trong môi trường network không ổn định (packet drop), tỉ lệ false-positive sẽ rất cao. Ngược lại, nếu được gán giá trị cao thì thời gian phát hiện lỗi sẽ tăng lên → Trade-off between speed and accuracy.
- Network message load:
O(N^2/T)với T là failure detection time
SWIM Protocol
Khác với giao thức heartbeat, SWIM protocol tách rõ ra 2 components chính:
- Failure Detector component: phát hiện failure trong hệ thống
- Dissemination component: phát tán thông tin về members join; left hoặc fail
Component 1: Failure Detector
Thuật toán
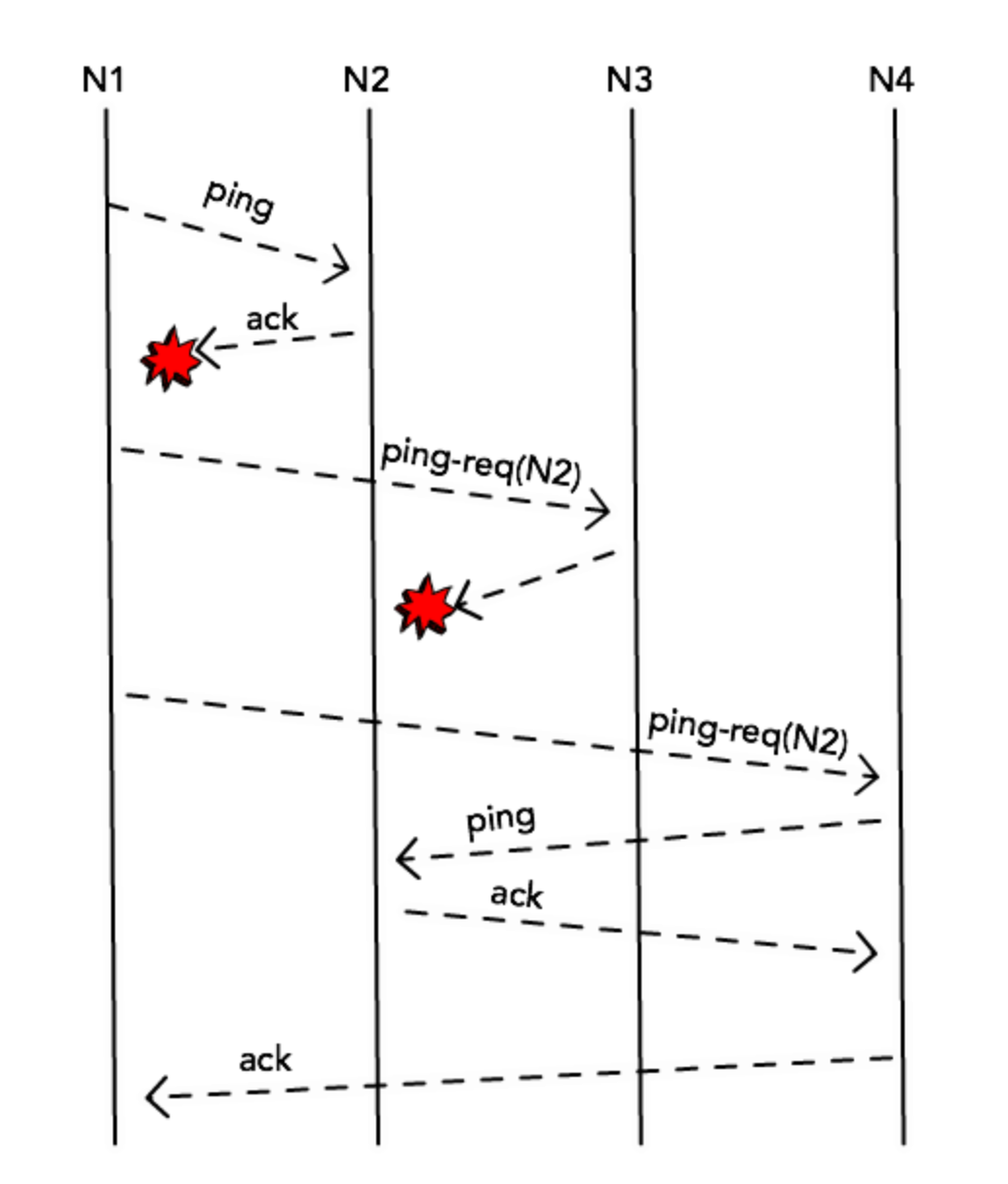
Xem xét một node bất kì, ở đây là N1.
- Ở một thời điểm bất kì, N1 sẽ chọn ngẫu nhiên một node trong hệ thống để kiểm tra xem node đấy có available hay - không, ví dụ ở đây là node N2. N1 sẽ send ping request tới N2.
- N2 sẽ gửi lại gói tin ACK cho N1. Trong trường hợp không nhận được gói tin ACK từ N2 (N2 bị down, slow network, hoặc- có vấn đề kết nối giữa N1 và N2), N1 sẽ chọn ra K node ngẫu nhiên khác trong hệ thống và gửi gói tin Ping(N2) để gián tiếp kiểm tra.
- Nếu không nhận được ACK từ bất kì node nào khác, N2 sẽ bị mark là down. Nói cách khác, nếu N1 nhận ít nhất 1 gói tin ACK, thì N2 sẽ “thoát” khỏi việc bị đánh dấu là down.
- Nếu N2 bị mark là down, sẽ move qua phase Dissemination
Đánh giá độ phức tạp: TODO
Component 2: Dissemination
Khi node M_j detect một member M_j fail, M_i sẽ gửi một gói tin là Fail(M_j) đến toàn bộ hệ thống. Node khi nhận được gói tin này sẽ delete M_j ra khỏi hệ thống. Việc thực hiện này tương tự Gossip protocol. Do vậy, có thể apply các thuật toán trong Gossip để tối ưu quá trình này.
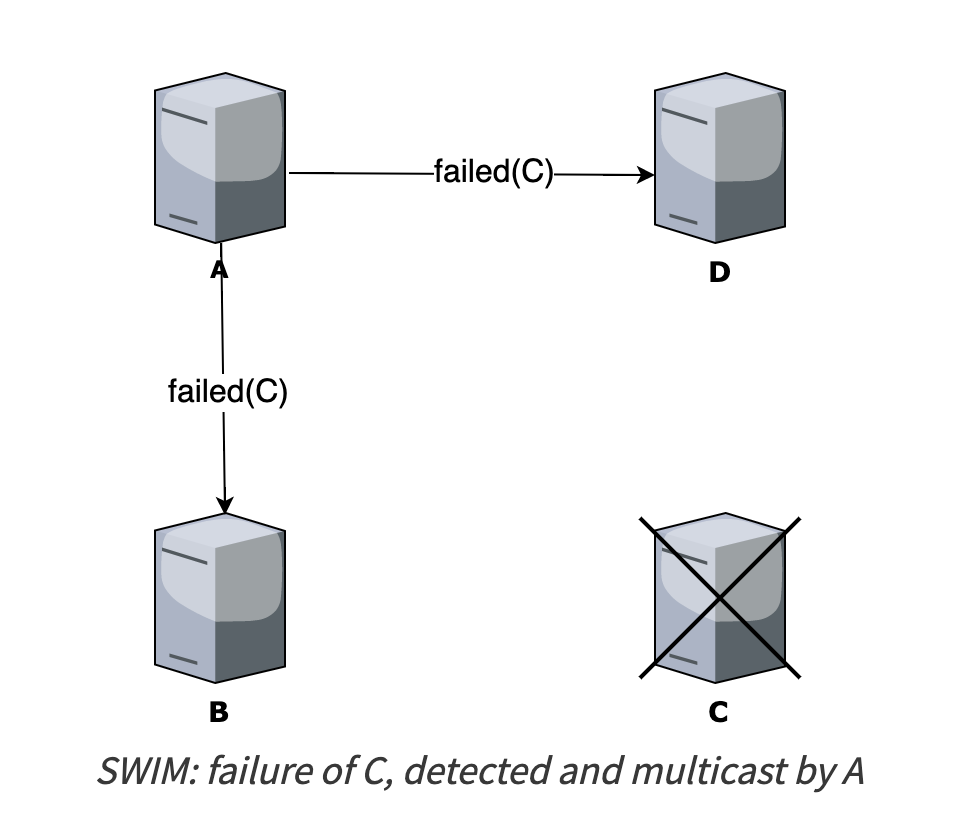
Optimization
Paper cũng đưa ra 3 cách optimization để cải thiện thuật toán.
Optimization 1: Suspicion Mechanism
Việc khi một node không thể ping được một node khác bằng cách trực tiếp hoặc gián tiếp và đánh dấu node đó bị crash trong nhiều trường hợp có thể ảnh hưởng tới hệ thống. Do vậy, có thể trade-off giữa thời gian detect một node bị crash và false-positive của failure detector bằng việc thêm vào một state trung gian là “suspect”.
Thuật toán:
- Khi node
M_ikhông ping được nodeM_jtrực tiếp hoặc gián tiếp, nodeM_isẽ chuyển state củaM_jtừ active -> suspect và truyền thông tin này cho toàn bộ các working node khác trong hệ thống. Node ở trạng thái suspect vẫn được coi là active trong các normal operations khác (ví dụ: vẫn được nhận gói tin của Dissemination component) - Khi
M_jnhận được gói tin suspect từ các node khác, sẽ gửi ngược lại gói tin alive. - Sau một thời gian timeout, nếu không nhận được gói tin timeout từ
M_j,M_jsẽ chính thức bị đánh dấu là crash.
State machine: (TODO)
Optimization 2: Round-Robin Probe Target Selection
Việc chọn random một node để send ping request dẫn đến việc delay việc detect một node bị crash. Ở trường hợp tệ nhất, node bị crash có thể sẽ không bao giờ được chọn để check và do vậy bị phát hiện. Do vậy, ta có thể đưa ra một improvement để tránh việc này xảy ra. Cụ thể:
- Khi một node bắt đầu start, node đấy sẽ random các peer.
- Khi một node chọn node tiếp theo để ping, sẽ chọn trên danh sách đã random ở trên theo thuật toán round-robin.
Ví dụ:
node 1: [4 2 3] Node 2: [4 1 3] Node 3: [1 2 4] Node 4: [3 2 1]Vì danh sách mỗi node là random nên công thức tính thời gian trung bình detect được node bị crash vẫn giữ nguyên. (distribution mỗi node được nhận gói ping request không thay đổi)
Nếu hệ thống có N nodes, thì tối đa 2*N-1 selection, một node M_i bất kì sẽ được chọn để gửi ping request –> bound time cho failure detection cho một node M_i bất kì. –> Time-bound completeness property.
Optimization 3: Infection-Style Dissemination Component
Ở phần trình bày trên, ta thấy có 3 loại request: ping / ping-req / ack . Tuy nhiên, ở group membership protocol, còn phải giải quyết thêm bài toán về leave/join group. Việc leave/join group này có thể implement bằng một giao thực Gossip nào đó. Tuy nhiên, việc này sẽ tăng lên message load trong hệ thống.
Có một cách để optimize quá trình này gọi là “piggyback”, nói cách khác, ta sẽ cố gắng “nhồi nhét” thêm các thông tin về gossip trong các gói tin ping / ping-req / ack. Điều này không làm tăng network load.
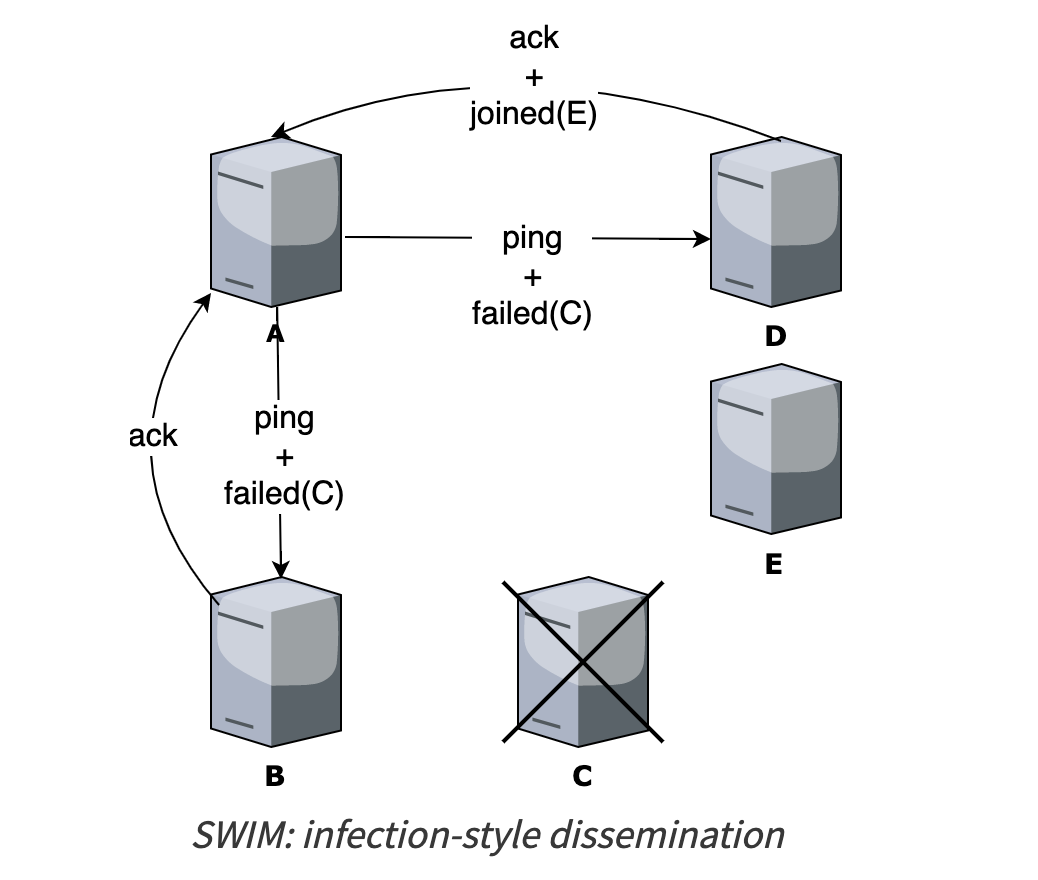
Ví dụ: A biết được C bị crash và D biết được E join vào mạng.
- Step 1: A thông báo với B rằng C đã chết -> B trả lời lại ack bình thường.
- Step 2: A tiếp tục thông báo với D rằng C đã chết. C trả lời lại ack, tuy nhiên kèm theo thông tin rằng E mới join - vào mạng.
- Step 3: A add thông tin về E vào danh sách các node trong hệ thống.
Evaluation (TBD)
- Strong completeness
- Speed of failure detection (liveness):
- Accuracy (safety):
- Network message load: