Giới thiệu về kiến trúc của Raft cùng các component chính. Song song đó đi vào chi tiết nội dung bầu chọn leader.
Phần 2: Thuật toán Raft
Giới thiệu
Raft - [R]eliable, Replicated, Redundant, [A]nd [F]ault-[T]olerant là thuật toán đồng thuận được công bố vào năm 2013. Các giả thiết khi thiết kế thuật toán:
- Mô hình mạng: xây dựng trên nền mạng đồng bộ ảo (virtual synchrony) - chạy lần lượt qua từng vòng, có timeout cho mỗi request.
- Mô hình chịu lỗi: có thể chịu được lỗi-và-phục-hồi (crash-recovery) - một máy tính sau khi dừng có thể phục hồi lại và tiếp tục chạy. Tuy nhiên, Raft không thể chịu được lỗi Byzantine - mỗi máy tính trong mạng đều chạy đúng theo thuật toán, và tin tưởng hoàn toàn các máy tính khác.
- Gói tin gửi đi có thể trùng lắp; mất hoặc đảo thứ tự khi nhận.
Kiến trúc
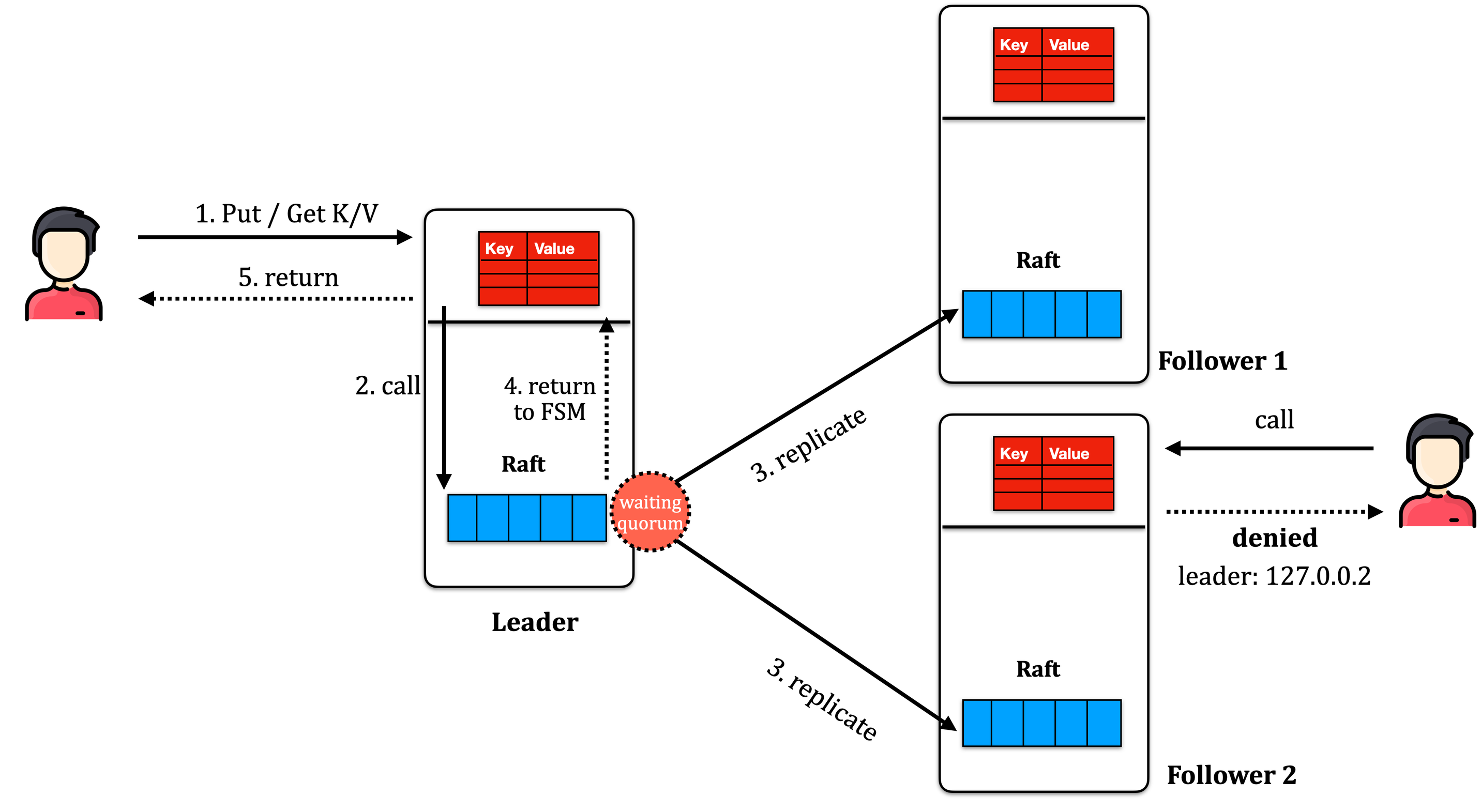 Hệ thống bao gồm nhiều node (mỗi node có thể là một máy tính / tiến trình chạy độc lập) và giao tiếp với nhau qua giao thức RPC. Ở mỗi node bao gồm 2 thành phần chính: Finite State Machine (màu đỏ) để chứa trạng thái hiện tại của hệ thống (thường là key-value database như ZooKeeper hoặc etcd) và Raft module (màu xanh).
Hệ thống bao gồm nhiều node (mỗi node có thể là một máy tính / tiến trình chạy độc lập) và giao tiếp với nhau qua giao thức RPC. Ở mỗi node bao gồm 2 thành phần chính: Finite State Machine (màu đỏ) để chứa trạng thái hiện tại của hệ thống (thường là key-value database như ZooKeeper hoặc etcd) và Raft module (màu xanh).
Quorum để chỉ về khái niệm số bầu chọn tối thiểu giữa các node (bao gồm cả node đề xuất phiếu bầu) để một thao tác (operation) được thông qua. Raft sử dụng quorum là [N/2] + 1, hay còn được gọi là “quá bán” xuyên suốt bài viết. Giá trị này rất quan trọng vì luôn đảm bảo 2 quorum sẽ luôn giao tại tối thiểu một node, và do vậy luôn có tối thiểu một node có thể thấy được hai hành vi từ 2 tác vụ khác nhau (nếu hợp lệ). Ví dụ: hệ thống có 3, 5, và 7 nodes thì quorum lần lượt là 2, 3 và 4. Từ đó, khả năng chịu lỗi được tối đa là (3-2=1), (5-3=2) và (7-4=3) node tương ứng.
Các hệ thống phân tán thường được triển khai với số node lẻ vì không có khác biệt về khả năng chịu lỗi khi số node chẵn nhưng đồng thời lại phải vận hành nhiều hơn một node. Ví dụ: hệ thống có 4, 6 và 8 nodes thì quorum lần lượt là 3; 4 và 5 nodes và số nodes tối đa có thể gặp lỗi là (4-3=1); (6-4=2) và (8-5=3) nodes, không khác với bộ 3, 5 và 7 nodes.
Trong hệ thống mạng, sẽ có một node đóng vai trò là leader và các node còn lại là follower. Chỉ có node leader mới được quyền trả lời cho người dùng. Lưu ý rằng có thể nhiều hơn một node “nghĩ rằng” mình là leader. Tuy nhiên, Raft đảm bảo mọi request đều phải được sự đồng ý từ quá bán từ các máy tính trong mạng. Do vậy, tuy rằng có nhiều hơn một node “nghĩ rằng” mình là leader, nhưng có tối đa một và chỉ một node tại một thời điểm bất kì có khả năng trả lời cho người dùng (giải thích phần trên).
Trong trường hợp bình thường, khi người dùng gửi request ghi tới node leader, quy trình thực thi sẽ là:
- API sẽ gọi xuống Raft module
- Raft module sẽ append request vào log module, sau đó gửi request ra toàn bộ mạng.
- Leader đồng thời sẽ chờ quá bán câu trả lời “đồng ý” từ các máy tính trong mạng (bao gồm chính leader) sau đó trả về FSM. FSM sẽ cập nhật bản ghi và trả kết quả cho người sử dụng.
Giải thích các thuật ngữ
State
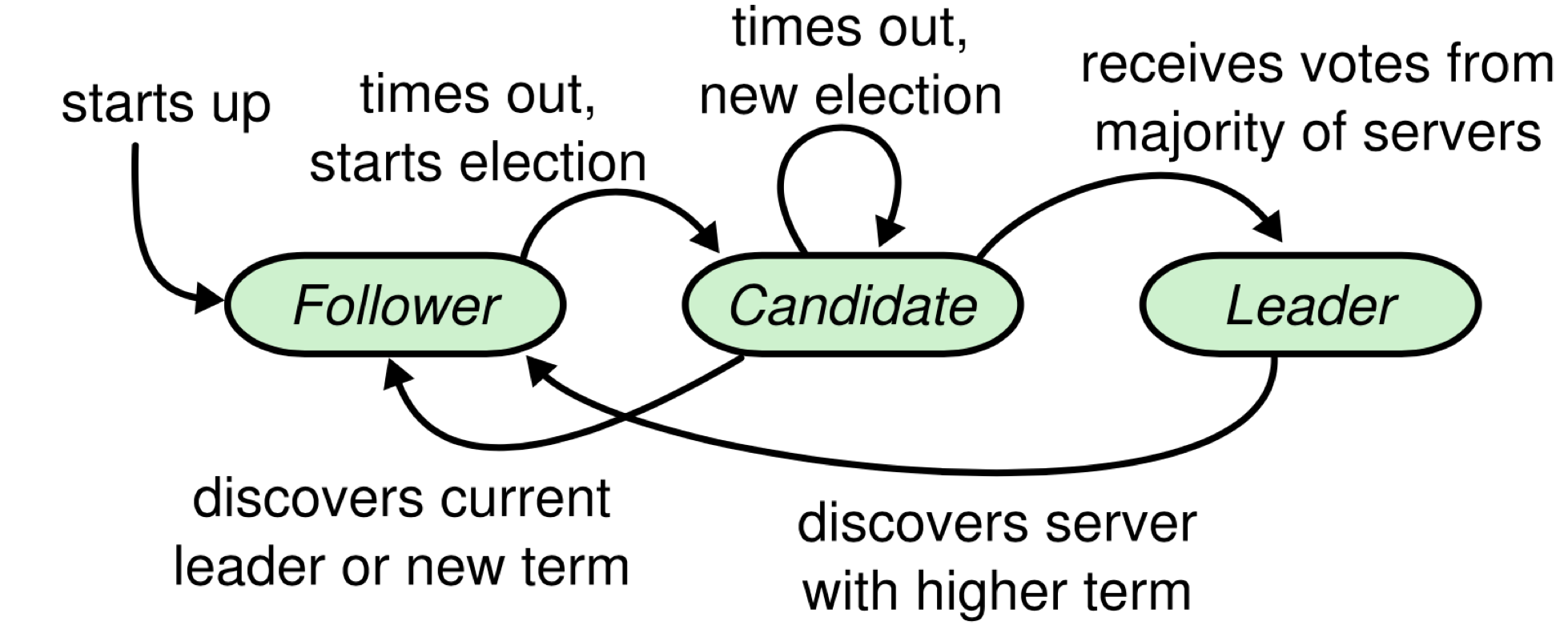
Mỗi node trên Raft sẽ có 3 trạng thái:
- Follower: chỉ giữ nhiệm vụ trả lời lại các lời gọi RPC trong mạng, và không được phép trả lời request từ phía người dùng (trừ việc trả về thông tin leader hiện tại cho người dùng để người dùng tự thay đổi hướng truy cập)
- Candidate: là trạng thái trung gian do Follower chuyển thành, cố gắng để trở thành leader.
- Leader: là node chủ động trong cluster. Leader sẽ nhận và xử lí request từ người dùng, và replicate log qua các node khác.
Term
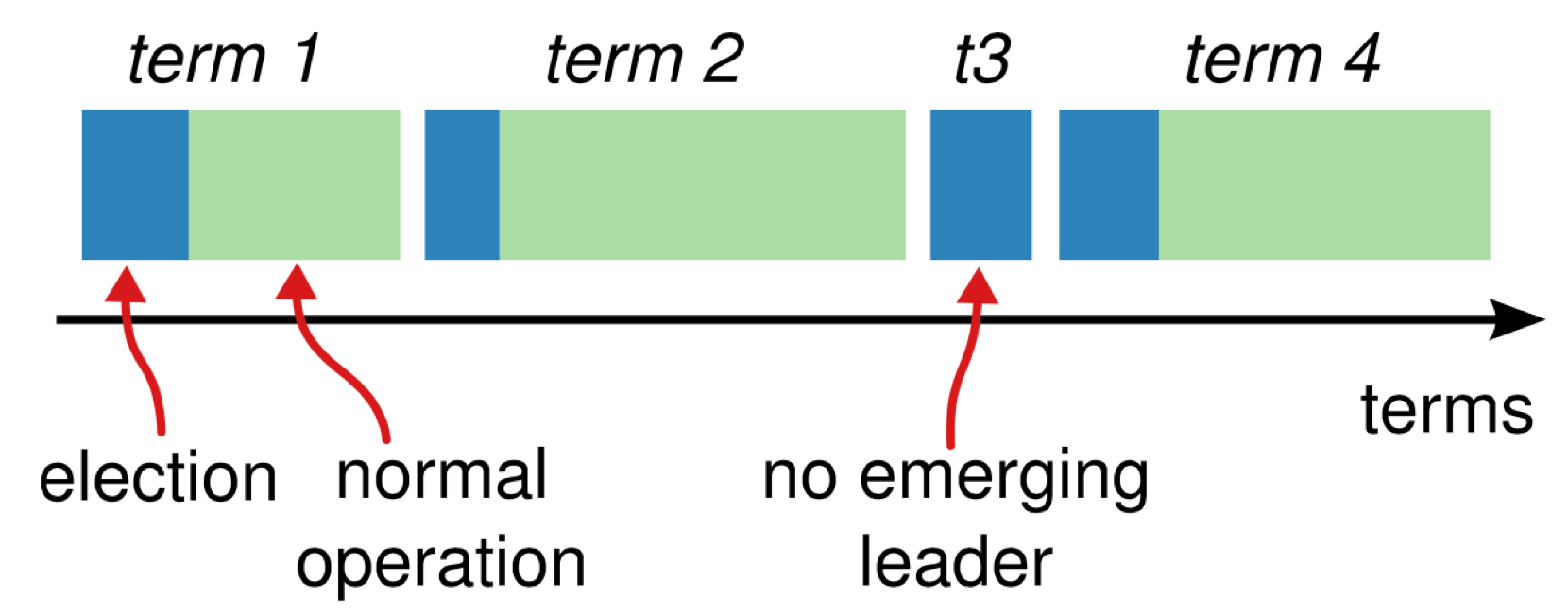
Term là số tự nhiên, đánh số liên tục, đóng vai trò như logical timestamp. Chỉ có tối đa một leader cho mỗi term. Thông tin về term luôn được trao đổi giữa các server mỗi khi gửi nhận message.
Log
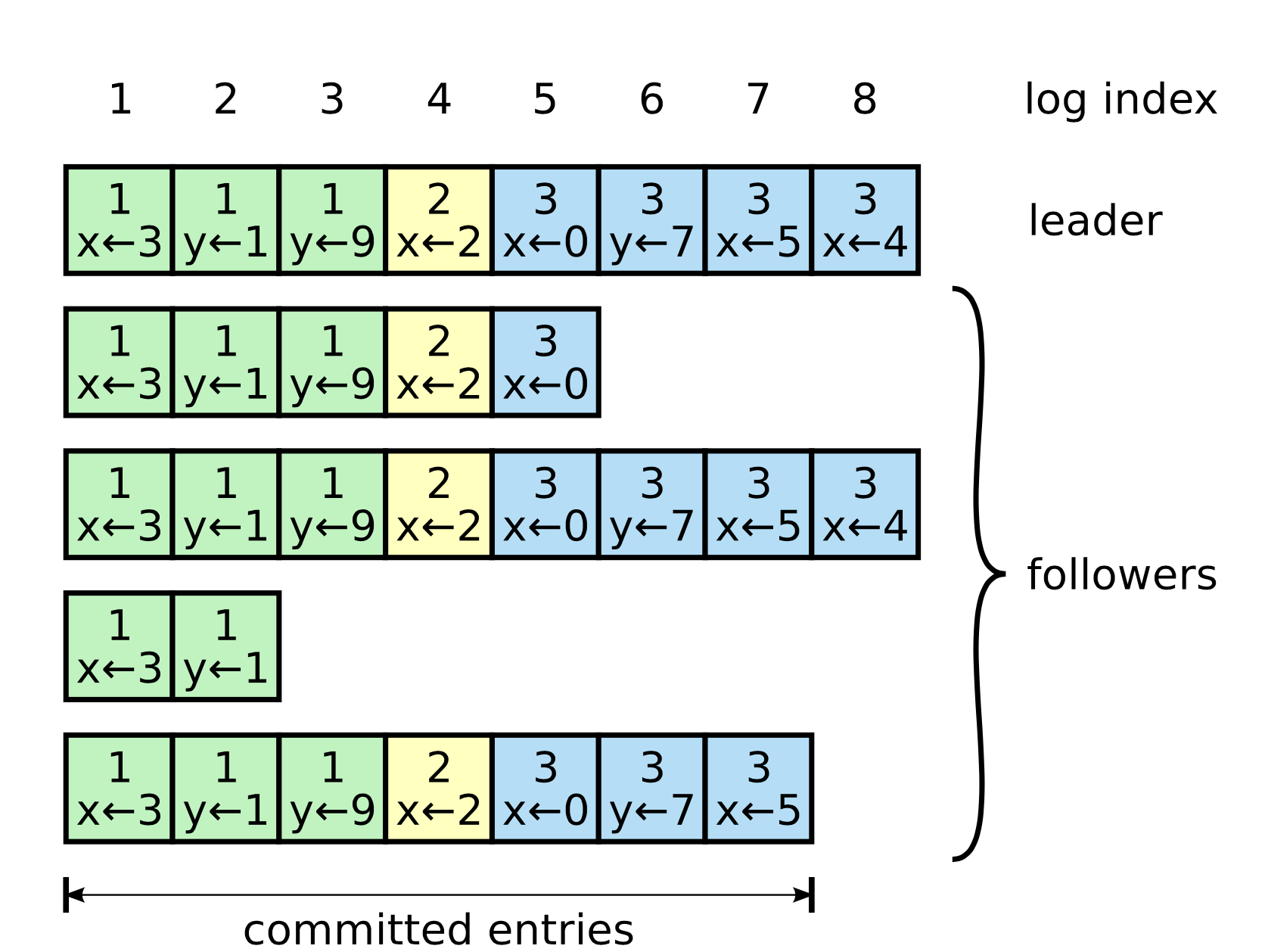
Hình minh họa trên mô phỏng lại chuỗi các log entry của các node. Các khái niệm cần nắm như sau
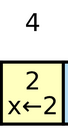
- Log Entry:
- bao gồm 3 thành phần: data + index + term. Log entry mới sẽ luôn được ghi nối vào hệ thống (append). Theo hình mình họa trên: index là 4; term là 2; data là “x<-2”. Lưu ý là data có thể là bất kì thông tin gì, không nhất thiết phải là một key-value.
- Log entry sẽ được lưu vào ổ đĩa ngay khi chèn vào mảng. Do vậy, hệ thống sẽ không bị mất dữ liệu khi xảy ra tình trạng crash.
- 2 log entry giữa 2 node được gọi là đồng nhất (identical) khi và chỉ khi data, index và term của chúng phải giống nhau từng đôi một. Do cách hoạt động của Raft, ta có thể đảm bảo rằng khi 2 log entry ở 2 node có chung index và term, chúng sẽ có cùng data, và do đó đồng nhất. Do vậy, trong quá trình hoạt động, ta thường chỉ so sánh 2 trường index và term giữa 2 log entry.
- Log index: tương tự như array index; tăng dần đều một đơn vị mỗi khi thêm một log entry vào mảng trên mỗi node. Lưu ý, theo như paper Raft đặc tả, log index bắt đầu từ 1.
- Committed entry: khi một log entry được gửi thành công trên quá bán node (bao gồm chính nó), log entry này sẽ được chuyển sang trạng thái committed. Khi log entry chuyển sang trạng thái committed, ta có thể an toàn update vào FSM và trả về cho client. Do vậy, trong hình minh họa trên, các log entry có index từ 1->7 được gọi là commited entry.
Request Type
Raft chỉ có 2 dạng request:
- RequestVote: dùng để bầu chọn leader.
- AppendEntries: được sử dụng trong 2 trường hợp
- Giao thức heartbeat. Khi đó, mảng các log cần replicate là empty
- Replicate log: thêm mảng các log entry cần replicate qua các follower.
Phân tích Raft
Có thể hiểu thuật toán Raft quy định 3 nội dung chính:
Bầu chọn Leader (Leader Election)
- Quy định giao thức để bầu chọn một node để trở thành leader
- Quy định cách follower phát hiện leader hiện tại dừng hoạt động để bầu chọn leader mới.
Log Replication
- Nhận request từ phía người dùng sau đó append vào log.
- Replicate log qua các node khác (và ghi đè những log ở trạng thái bất đồng bộ)
Safety
- Đảm bảo logs consistent giữa các node
- Chỉ có node có log up-to-date mới được trở thành leader.
Bầu chọn Leader
Leader sẽ sử dụng request RequestVote để gửi thông tin ra toàn mạng.
| Arguments | |
|---|---|
| term | candidate’s term |
| candidateID: | định danh của candidate |
| lastLogIndex: | index candidate’s log entry cuối cùng |
| lastLogTerm: | term candidate’s log entry cuối cùng |
| Result | |
| term | trả về term hiện tại, cho phép candidate cập nhật lại term mới hơn |
| voteGranted | true nghĩa là follower đồng ý để candidate trở thành leader |
Thuật toán bầu chọn leader có thể tóm tắt qua sơ đồ sau
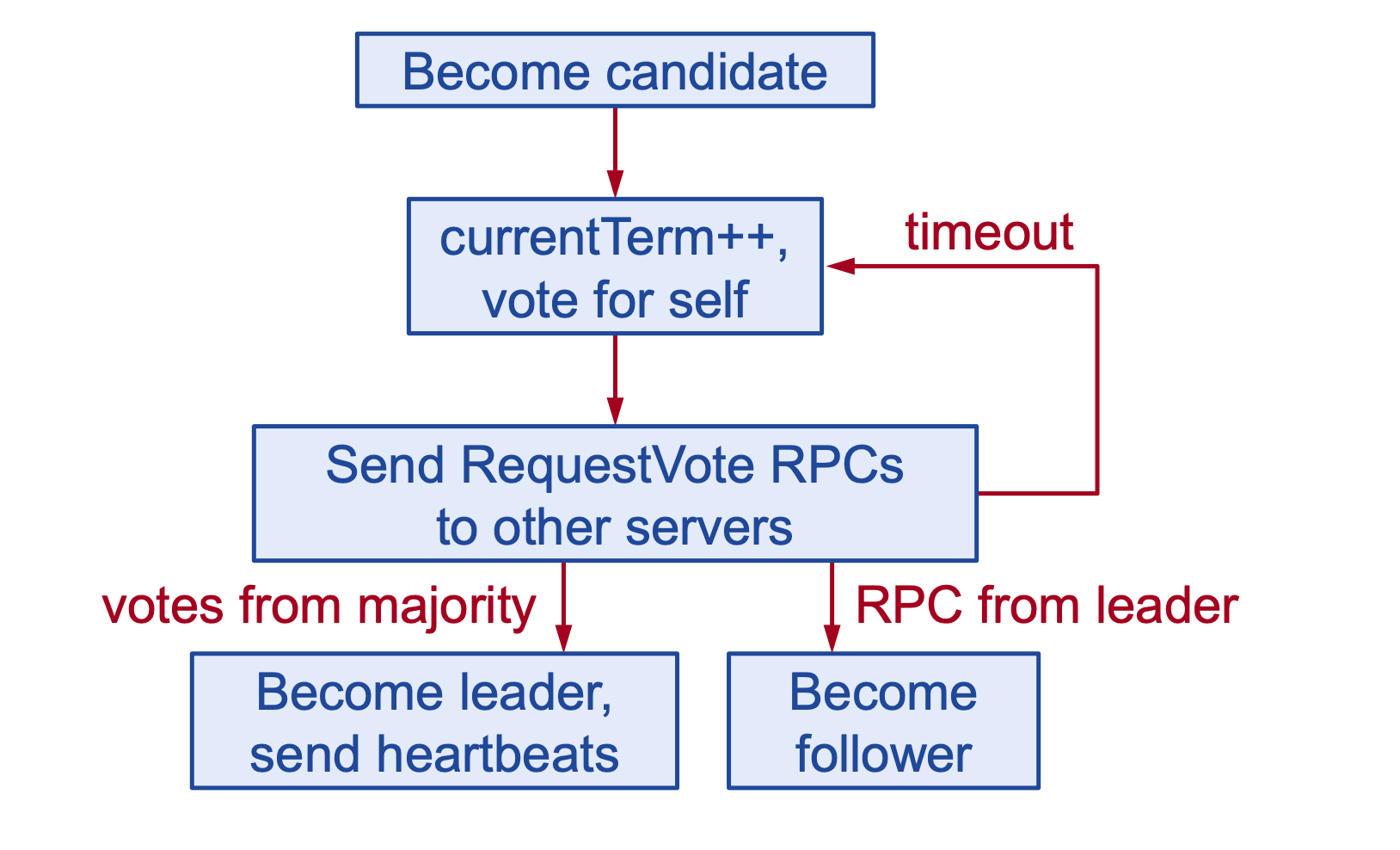
Khi hệ thống khởi động, các node sẽ bắt đầu ở trạng thái Follower. Sau một thời gian timeout khi không nhận được tín hiệu từ Leader, node sẽ tự chuyển từ trạng thái Follower qua Candidate.
Giai đoạn 1: Khi candidate bắt đầu xử lí và gửi request RequestVote ra toàn mạng:
- Candidate sẽ tăng term hiện tại lên 1. Sau đó, gửi request
RequestVotecho toàn bộ các node khác trong hệ thống. - Các node khác trong hệ thống khi nhận được request RequestVote sẽ kiểm tra các điều kiện để xem candidate có thể trở thành leader được hay không. Cụ thể là:
- Term của candidate phải cao hơn term hiện tại để tránh tình trạng
RequestVotetừ một candidate rất cũ trong quá khứ. - Log của candidate phải up-to-date hơn log của node hiện tại. (giải thích phần sau).
- Term của candidate phải cao hơn term hiện tại để tránh tình trạng
Giai đoạn 2: Khi candidate nhận được kết quả từ RequestVote gửi đi:
- Nếu term trả về lớn hơn term hiện tại: Candidate hiểu rằng mình đã bị outdate, liền chuyển trạng thái từ Candidate về Follower, và đợi phản hồi từ leader mới trong hệ thống.
- Nếu đồng ý: tăng số lượt bầu chọn lên 1.
Từ đây sẽ có 2 khả năng cho các kết quả trả về:
- Nếu timeout nhưng không nhận đủ quá bán số bầu chọn: term hiện tại đã không nhận được đủ số đồng thuận, candidate liền tiếp tục tăng term lên 1 và bắt đầu lại quá trình bầu chọn leader.
- Nếu đạt được quá bán số bầu chọn: chuyển từ trạng thái Candidate sang Leader, gửi request “PING” ra toàn mạng, bắt đầu quá trình Log Replication và cho phép nhận request từ phía client.
Câu hỏi: Có khả năng quá trình bầu chọn diễn ra vô thời hạn ?
Trả lời: Có thể. Và điều này hợp lí theo định lí FLP Impossibility: không tồn tại thuật toán đồng thuận chạy kết thúc được hết trong mọi tình huống thực thi.
Khi Leader bị crash, có thể toàn bộ các node Follower nhận ra tại cùng một thời điểm và chuyển qua trạng thái Candidate. Do vậy, việc bầu chọn diễn ra nhưng không ai dành được đa số. Sau khi cùng timeout, các candidate cùng tiếp tục lại quá trình khởi tạo leader ở term mới. Quá trình này có thể diễn ra liên tục và vô thời hạn.
Do vậy, theo như paper, khi một node trở thành candidate, node này sẽ random một giá trị timeout cho việc chờ đợi thời gian bầu chọn. Do vậy, khả năng các node cùng timeout diễn ra rất thấp, và sẽ có một node timeout đầu tiên. Node này sẽ bắt đầu quá trình bầu chọn leader ở term mới và có thể dễ dàng đạt được đồng thuận hơn.
Điều kiện “up-to-date” ta bàn ở phần trên là gì ?
candidate’s last entry term > follower’s last entry term
OR
candidate’s last entry term == follower’s last entry term AND candidate’s log length > follower’s log length
Đây là điểm khác biệt lớn giữa Raft và Multi Decree Paxos:
- Multi Decree Paxos: điều kiện cho bầu chọn leader đơn giản hơn so với Raft. Do vậy không đảm bảo được leader sẽ có đủ thông tin về toàn bộ log trong hệ thống. Dẫn đến ở giai đoạn Log Replication quá trình sẽ diễn ra phức tạp hơn để đạt được đồng bộ về log giữa các node.
- Raft: Điều kiện cho bầu chọn leader chặt hơn: phải đảm bảo yêu cầu candidate chắc chắn có đủ toàn bộ thông tin về các log entry đã được replicate quá bán ra toàn mạng mới được bầu chọn thành Leader (do đó tại sao điều kiện này được đặt tên là up-to-date ). Do Raft đảm bảo chặt điều kiện này, khi một node trở thành leader, node này đảm bảo chứa đủ toàn bộ thông tin về log entry đã replicated được quá bán trong hệ thống. Từ đó, giai đoạn đồng bộ log trở nên đơn giản hơn, leader chỉ còn giữ nhiệm vụ đồng bộ log từ leader qua các node follower ở trạng thái bất đồng bộ.
Câu hỏi: Một suy nghĩ rất tự nhiên là tại sao ta không đơn giản quy định “node nào có log độ dài lớn hơn thì sẽ “up-to-date” ?
Trả lời:
Điều này không chính xác với tình huống sau:
S1: 5 6 7
S2: 5 8
S3: 5 8
Giả sử ở term thứ 9 S1 trở thành leader, khi đó trạng thái về log sẽ là:
S1: 5 6 7 9
S2: 5 8
S3: 5 8
Sau đó, S1 replicate log qua toàn bộ các node khác (leader không bao giờ xoá/sửa log trên chính nó)
S1: 5 6 7 9
S2: 5 6 7 9
S3: 5 6 7 9
Điều này vô lí, vì log ở term 8 đã được replicate qua quá bán và bị mất. Tuy nhiên, liệu một kịch bản như vậy có thể xảy ra trên thực tế ? Câu trả lời là Có với kịch bản sau
| Raft Log | Giải thích |
|---|---|
| S1: 5 S2: 5 S3: 5 |
- S1 là leader của term 5. Người dùng gửi một request tới S1 và S1 đã kịp replicate log ra toàn mạng. - Sau đó, S1 bị crash và fast-restart trước khi các node khác nhận được time out - S1 start quá trình bầu chọn ở term 6. |
| S1: 5 6 S2: 5 S3: 5 |
- S1 là leader của term 6 - Người dùng gửi request vào S1 tại term 6. Log sẽ được append vào local của S1. - S1 chưa kịp replicate log qua các node khác thì node S1 bị crash và fast-restart trở lại. |
| S1: 5 6 7 S2: 5 S3: 5 |
- S1 tiếp tục là leader của term 7 - Tương tự như trên, Người dùng gửi request vào S1 ở term 7 - Tương tự, S1 chưa kịp replicate log qua các node khác thì node S1 bị crash |
| S1: 5 6 7 S2: 5 8 S3: 5 8 |
- Lần này, các node khác nhận ra S1 bị crash do timeout, khởi tạo quá trình bầu chọn. - S2 trở thành leader tại term 8. - Người dùng gửi request vào S2 tại term 8. - S2 replicate log qua S3. Log ở term 8 đã được quá bán, do vậy chắc chắn data tại term 8 luôn buộc phải được giữ và không bao giờ được xóa đi. (A) |
|
S1: 5 6 7 9 S2: 5 8 S3: 5 8 |
- Sau khi S1 phục hồi, bắt đầu lại quá trình bầu chọn leader với term 9 - Nếu ta chọn giải pháp “candidate nào có độ dài log dài hơn là leader” —> S1 sẽ chiến thắng - Khi đó, log ở S1 sẽ replicate qua S2 và S3 (log ở leader không bao giờ xoá). Vô lí với phát biểu (A) |
| S1: S1: 5 6 7 S2: 5 8 S3: 5 8 |
Tuy nhiên, nếu ta sử dụng điều kiện up-to-date như trong paper phát biểu: - Last log entry’s term của S1: 7 - Last log entry’s term của S2: 8 Do 7 < 8, điều kiện up-to-date không thỏa mãn, do vậy S2 sẽ từ chối cho S1 trở thành leader. |
Trong phần tiếp theo, chúng ta sẽ đi qua chi tiết về cách Raft replicate log giữa các máy tính và cách Raft xử lí việc log không đồng bộ.