Đi qua các vấn đề khác về Raft như một số trường hợp đặc biệt khi thực thi; tương tác giữa client và Raft server cùng các nguồn tham khảo khác để tìm hiểu thêm.
Các vấn đề khác liên quan Raft
Commit log entry ở term trước
Như trình bày ở phần kiến trúc tổng quát, khi leader nhận được quá bán request đồng ý khi replicate một log entry ở vị trí T, leader sẽ commit log entry này (apply vào FSM và trả kết quả về cho client).
Phần này, ta sẽ nói rõ hơn một trường hợp đặc biệt: log entry đã được replicate qua quá bán các node nhưng ở một term cũ hơn so với term hiện tại leader đang chạy, leader sẽ không lập tức commit log entry này.
Ta sẽ minh hoạ việc này qua hình vẽ sau:
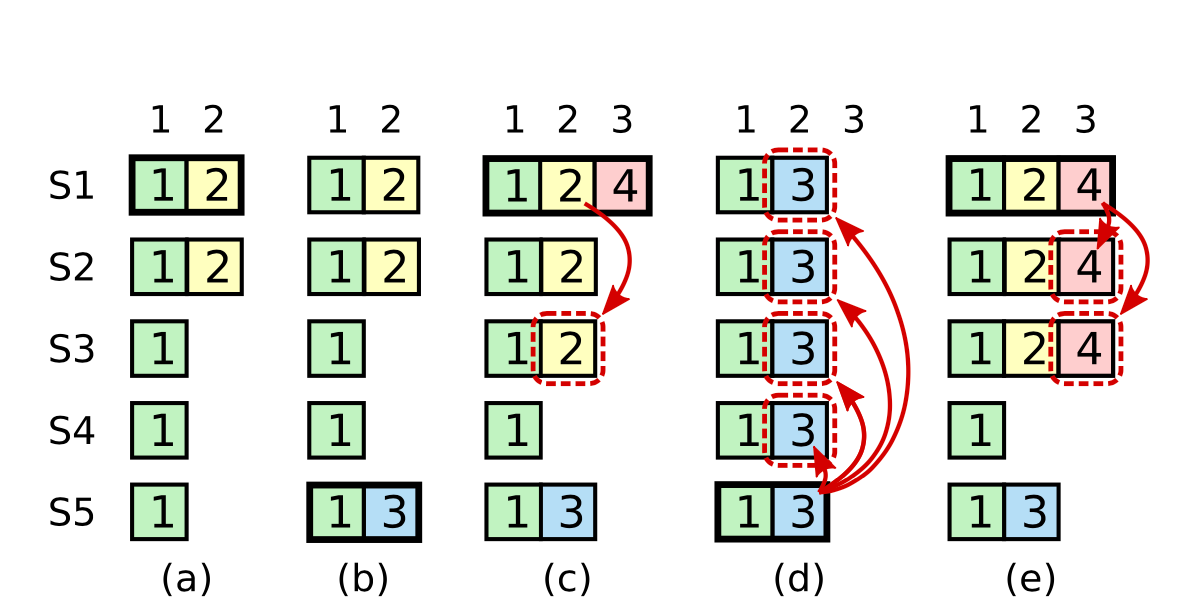
- Cột a: S1 là leader ở term 1 và 2 và đã replicate một phần log entry ở term 2 (màu vàng)
- Cột b: S1 crash, S5 trở thành leader ở term 3 do nhận được bầu chọn từ S3 S4 và S5 (do vậy vẫn thỏa mãn tính tính chất up-to-date trong leader election - S2 chắc chắn sẽ reject S5 do điều kiện up-to-date). Sau đó, S5 đã accept một log entry ở term 3 tại index 2 như hình vẽ.
- cột c: S5 crash, S1 khởi động lại và được bầu chọn làm leader ở term 4. Theo như phân tích về log replication ở phần trước, log ở term 2 (màu vàng) sẽ được replicate qua các node khác. Sau đó S1 accept thêm một log entry ở term 4 tại index 3 như hình vẽ. Ta lưu ý: tại thời điểm này, log entry ở term 2 đã xuất hiện trên quá bán, nhưng ta vẫn chưa commit. Ta sẽ hiểu rõ hơn tại sao thông qua trường hợp ở cột d.
- cột d: Nếu S1 crash và S5 trở lại làm leader ở term 5 (với vote từ S2; S3 và S4) và ghi đè toàn bộ nội dung log ở các node khác bằng log entry ở term 3. Lưu ý: Ta lại tiếp tục thực hiện quy luật là chưa commit log ở term 3 dù đã xuất hiện quá bán các node (do đang chạy trên term là 5)
- cột e: Minh hoạ một trường hợp S5 không thể trở thành leader. Nếu ở (c), leader S1 khi đó kịp thời replicate log entry ở term 2 và 4 ra quá bán các node, thì S5 không thể dành được đa số phiếu bầu để trở thành leader được (không thoả mãn tính chất log phải up-to-date)
Giải thích: Qua ví dụ trên, ta thấy nếu từ vị trí cột c, ta cho phép log ở term 2 commit (trả về cho client), sau đó log tại vị trí này có thể bị override tại thời điểm tương lai (cột d) → tạo ra trạng thái inconsistent trong hệ thống (xoá đi một log đã được commit). Do vậy, ta sẽ không bao giờ commit trực tiếp một log entry ở term nhỏ hơn term hiện tại bằng phương pháp đếm số node đã replicate trên chính entry đó.
Giải pháp: chỉ có log entry tại term hiện tại được phép commit bằng phương pháp đếm số replicas.
Do cách chúng ta replicate, các log entry trước đó sẽ gián tiếp được commit theo. (tuân theo định lí Log Matching Property). Tuy rằng có một số trường hợp đặc biệt (ví dụ như nếu log entry đó đã được replicate qua toàn bộ các node, ta có thể an toàn commit), Raft chọn giải pháp này để thiết kế đơn giản nhất.
Nhận xét
- So với Paxos, Raft phức tạp hơn ở điểm này. Ở thuật toán Paxos, nếu leader muốn replicate lại một log entry ở term cũ hơn, Paxos sẽ phải ghi đè với term hiện tại (cùng với một số điều kiện ràng buộc khác). Với Raft, một log entry khi tạo ra sẽ cố định term xuyên suốt quá trình chạy giữa các máy tính trong mạng. Thiết kế này có điểm tốt là dễ lí luận hơn về các log entry khi được truyền trong mạng.
- Trong trường hợp như ở cột (c), nếu sau khi S4 lên làm leader nhưng đồng thời không nhận được bất cứ request nào mới từ client, có thể các entry ở term 2 và term 4 không bao giờ được commit. Đây là lí do mà một số thư viện implement Raft, ví dụ như tikv/raft-rs, leader ngay sau giải đoạn leader election sẽ tạo ra một no-op message nhằm mục đích buộc quá trình commit này diễn ra trên toàn bộ log entry cũ.
Tương tác với client
Như trình bày ở phần kiến trúc tổng quát, client sẽ gọi tới master để thực hiện việc đọc ghi. Với việc ghi, truy vấn buộc phải truy xuất trên node master. Tuy vậy, vẫn sẽ nảy sinh một số vấn đề trong giao tiếp giữa client và Raft cluster.
Linearizability Read
Linearizability, hay còn gọi là recency guarantee. Do vậy, linearizability read buộc phải trả về data mới nhất ngay tại thời điểm gửi request. Một vấn đề có thể gặp phải: nếu client đọc trên một node là leader ở một term cũ, leader đó có thể trả về dữ liệu cũ → vi phạm thuộc tính “mới nhất”.
Một cách đơn giản là Raft sẽ coi thao tác đọc tương tự thao tác ghi: Leader sẽ tạo ra một log entry và đợi cho log entry đó được commit (đồng nghĩa đã được replicate qua quá bán các node trong mạng) sẽ trả kết quả về cho client. Tuy vậy, điều này ảnh hưởng nghiêm trọng tới hiệu suất hoạt động của toàn hệ thống. Ta có thể đảm bảo linearizability read mà không cần phải sử dụng log bằng cách:
- Leader phải có thông tin về commited log mới nhất: Theo như định lí Leader Completeness Property, leader lúc này chắc chắn có hết log entry đã được commit. Tuy nhiên, ta không rõ được chính xác là tới log entry nào (log của leader khi đó có thể bao gồm cả những log entry mà chưa được commit). Do vậy, leader cần phải commit ít nhất một log entry tại term hiện tại ra toàn mạng. (xem lại phần “Commit log entry ở term quá khứ” để hiểu rõ lí do). Raft chọn giải pháp xử lí bằng cách gửi một no-op message vào log ngay tại thời điểm mới bắt đầu trở thành leader → replication → commit.
- Leader phải đảm bảo bản thân là leader mới nhất hiện tại: gửi và chờ nhận được quá bán số heartbeat request (a.k.a: empty AppendEntries) trong mạng, trước khi trả kết quả về cho client.
Follower Read
Theo đặc tả, Raft sẽ phục vụ mọi request ở leader, ngay cả trong trường hợp read-only. Nếu ta có thể giảm tải ở leader thì hệ thống có thể scale out dễ dàng hơn. Một ý tưởng nảy sinh: Đó là chúng ta sẽ phục vụ read-only request ở node follower.
Thuật toán có thể biểu diễn như sau:
- Bước 1: Follower gửi yêu cầu
ReadIndextới leader - Bước 2a: Leader đọc latest committed index
- Bước 2b: Leader cần chứng thực vẫn đang là leader của term hiện tại bằng việc broadcast heartbeat ra toàn mạng.
- Bước 2b: Leader trả committed index về lại cho follower
- Bước 3a: Follower đọc được latest committed index, nếu dữ liệu trên node chưa được cập nhật tới index này, Follower sẽ sync up dữ liệu với leader
- Bước 3b: Sau khi sync up dữ liệu thành công, follower trả data về lại cho người dùng
Như vậy, ta vẫn có thể đảm bảo được tính Linearizability cho dù thực thi request ở node Follower.
Để tránh việc giai đoạn này diễn ra liên tục, ta có thể optimize hơn bằng cách hiện thực LeaseRead, và phải đảm bảo thời gian cho leader lease ngắn hơn thời gian timeout để bầu chọn một leader mới.
Trên thực tế, Follower vẫn phải gửi một network request đến leader. Do vậy, optimization này không cải thiện đáng kể latency, nhưng giúp giảm tải ở Leader, do vậy có thể tăng được read throughput.
Idempontent Processing
Một trường hợp có thể xảy ra trong thực tế: leader sau khi commit log entry (đồng nghĩa việc đã replicate data qua quá bán các node) nhưng lại bị crash trước khi trả về cho client. Client do vậy tiếp tục gửi request tới node là master ở term mới, và do vậy request sẽ bị xử lí hai lần. Raft đề xuất một cách xử lí:
- Client sẽ assign ID tăng dần và duy nhất cho mỗi request ghi. State machine sẽ lưu giữ thông tin request id lớn nhất đã xử lí cho mỗi client id, cùng với response tại thời điểm đó. Nói cách khác, đây là một mapping giữa ClientID → (Max Process ID, ExpectedResponse)
- Nếu server nhận ra đây là một request đã xử lí, trả về ExpectedResponsengay lập tức mà không cần thực thi request (lưu ý: không phải là trạng thái mới nhất của state machine).
Đây cũng là cách xử lí chung trong hệ thống phân tán nói chung, và các thuật toán đồng thuận khác (e.g.: ViewStamp Replication / ZooKeeper Atomic Broadcast) nói riêng.
Các vấn đề khác
Ta đã đi qua 2 nội dung chính của thuật toán Raft là bầu chọn Leader và Log Replication. Với hai cơ chế này, Raft đảm bảo được tính đồng thuận giữa các máy tính trong hệ thống mạng nội bộ. Tuy nhiên, có rất nhiều vấn đề phát sinh khi vận hành hệ thống. Ta sẽ điểm qua một số bài toán chính.
Log Compaction
Nếu không có cơ chế dọn dẹp những log entry cũ, lưu trữ trên mỗi node sẽ liên tục phình to dù các log entry đã được replicate ra toàn bộ hệ thống. Ví dụ [x -> 1; x -> 2] có thể thành [x->2] Tuy nhiên, khó khăn đặt ra nếu ta “vô tình” xoá đi những log entry mà chưa được replicate qua các server khác, ta sẽ không thể phục hồi lại được.
Paper Raft có đặc tả rất rõ về cách giải quyết bài toán này. Tuy nhiên, do khuôn khổ bài viết, nội dung sẽ không được trình bày.
Cấu hình thay đổi lúc vận hành
Ở thời điểm khởi đầu hệ thống, các máy tính biết được số lượng máy và địa chỉ các từng máy trong mạng. Tuy nhiên, trong quá trình vận hành, ta muốn scale-up hệ thống bằng cách bổ sung nhiều node hơn vào trong mạng.
Khó khăn đặt ra khi ta muốn zero-downtime trong lúc deployment và đồng thời đảm bảo tính consistency của hệ thống.
Chủ động chuyển quyền leader
Một số trường hợp ta muốn chuyển quyền leader qua máy tính khác lúc vận hành:
- Maintainace: Ví dụ ta muốn bảo dưỡng máy tính đang đóng vai trò là leader nên cần phải shutdown/restart lại máy.
- Performance: Máy tính khác trong mạng ở một số trường hợp phù hợp hơn để làm leader. Ví dụ máy tính đang đóng vai trò là leader trong tình trạng high-load khó có khả năng tiếp tục xử lí request tiếp. Hoặc ta muốn chọn một máy tính trong mạng có độ trễ nhỏ nhất tới người dùng để làm leader.
Ở các trường hợp này, ta có thể đơn giản tắt hẳn máy tính đang làm leader và theo thuật toán Raft, các node khác có thể bầu chọn ra một leader mới. Tuy nhiên, cách này không chủ động trong việc chọn leader mới, và sẽ bị một giai đoạn downtime trong lúc vận hành.
Ta có thể tối ưu quá trình này bằng cách chủ động chuyển quyền leader giữa các node với nhau.
Partial Network Fault
Trong khi vận hành, các node có thể không có thông tin kết nối đầy đủ với các node khác trong hệ thống. Trong nhiều trường hợp, điều này dẫn tới hệ thống không thể bầu chọn được leader, hoặc việc bầu chọn diễn ra không ổn định, ảnh hưởng tới hoạt động toàn hệ thống.
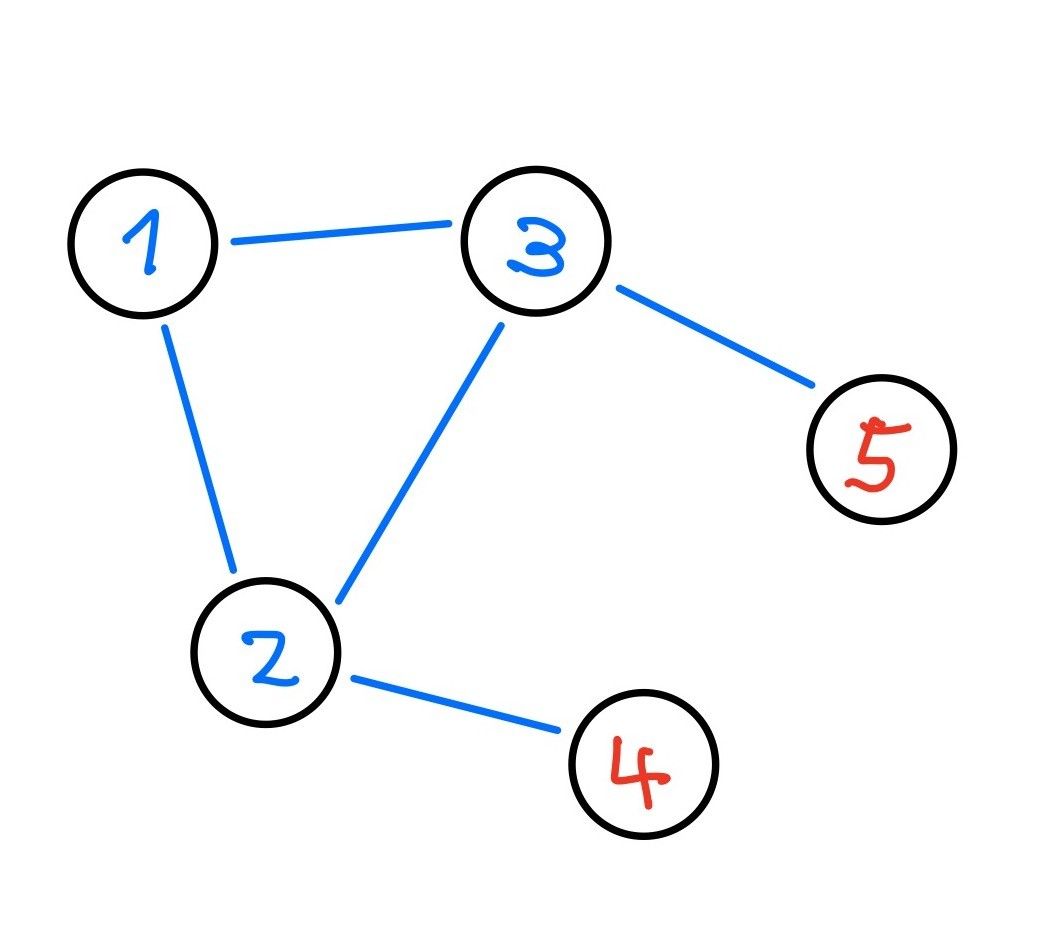
Ví dụ với đồ thị kết nối như trong hình, và node 1 đang là leader.
- Do node 4 không nhận được tín hiệu từ leader 1, node 4 sẽ tăng term lên 1, và khởi tạo quá trình bầu chọn leader. Khi đó node 2 sẽ cập nhật thông tin, động thời buộc leader 1 lui xuống thành follower.
- Sau một thời gian, node 1 không nhận được tín hiệu từ leader trong mạng, khởi tạo quá trình bầu leader cho chính nó và trở thành leader. Node 2 tiếp tục cập nhật thông tin và buộc node 4 trở về lại trạng thái follower.
- Tuy nhiên, khi đó ta lại quay lại trường hợp đầu: node 4 bị timeout và tiếp tục khởi tạo quá trình bầu leader. Do vậy, việc bầu leader trở nên không ổn định.
Bài toán Byzantine
Nếu có một máy tính không theo protocol: luôn reply “accept” cho mọi RequestVote request, nhưng đồng thời lại không accept request đó ở local và gửi RequestVote cho mọi node khác ở term lớn hơn. Hành vi này có thể khiến cho mọi lần bầu chọn không thể chọn được leader do khả năng bị chia phiếu (split-vote).
Tham khảo
Sau đây là một số nguồn tham khảo để xây dựng nên bài viết. Song song cũng có những nguồn tham khảo khác để củng cố hơn hiểu biết xoay quanh thuật toán Raft.
1. Paper: In Search of an Understandable Consensus Algorithm (Diego Ongaro, John Ousterhout - 2013)
Paper nguyên bản về Raft: chi tiết về cách implement và chứng minh tính đúng đắn của thuật toán.
2. Paper: Raft Refloated: Do We Have Consensus? (Heidi Howard, et cetera - 2015)
Thử nghiệm Raft và benchmark Raft trên những cấu hình khác nhau.
3. Paper: Paxos vs Raft: Have we reached consensus on distributed consensus? Heidi Howard, Richard Mortier - 2020)
So sánh những khác biệt cơ bản giữa Multi-decree Paxos và Raft.
4. Video lecture
- Raft user study: Raft lecture https://www.youtube.com/watch?v=YbZ3zDzDnrw
- Raft user study: Paxos lecture https://www.youtube.com/watch?v=JEpsBg0AO6o
Hai video lecture của đại học Stanford về 2 thuật toán đồng thuận là Raft và Paxos. Theo như trong báo cáo, nhóm sinh viên học Raft trước Paxos sẽ dễ dàng có điểm cao hơn nhóm các sinh viên học Paxos trước Raft.
5. MIT Course 6.824: Distributed System
Một khóa học rất hay và thực tế từ MIT cho bậc học master về hệ thống phân tán. Có đủ bài tập và test cho phép người học tự implement và kiểm tra kết quả.
6. https://github.com/hashicorp/raft Hiện thực hóa thuật toán Raft bằng ngôn ngữ Golang. Thư viện này được sử dụng trong etcd do vậy đã được battle-test rất cẩn thận. Project này là nguồn quý giá để so sánh khác biệt giữa Raft được nêu trong paper và được implement trên các hệ thống chạy thực tế.
7. https://hqt.github.io/2021-03-01-raft-proof/
Paper về Raft có trình bày chứng minh tính đúng đắn của thuật toán, tuy nhiên rất cô đọng. Bài blog trên sẽ làm rõ các ý trong phần chứng minh.
8. Paper: Virtual Consensus in Delos (Mahesh Balakrishnan, et cetera, Facebook - 2020)
Một hệ thống khi đã sử dụng một thuật toán đồng thuận rất khó để thử nghiệm hoặc đổi qua một thuật toán khác.
Bài báo cáo đề xuất ý tưởng trừu tượng hóa đồng thuận bằng cách xây dựng một lớp API trừu tượng về Log mà ở tầng ứng dụng không cần quan tâm về đặc tả kĩ thuật của thuật toán đồng thuận. Đằng sau lớp API ta có thể sử dụng một hay nhiều thuật toán đồng thuận cùng lúc. Hệ thống này đã được sử dụng ở Facebook.
9. Paper: Impossibility of Distributed Consensuswith One Faulty Process (Fischer; Lynch; Paterson - 1985)
Paper phát biểu và chứng minh định lí FLP Impossbility ảnh hưởng lớn tới cộng đồng nghiên cứu hệ thống phân tán. Năm 2001, paper được trao giải Dijkstra - giải thưởng tôn vinh những nghiên cứu ảnh hướng lớn tới cộng đồng hệ thống phân tán, bắt đầu từ năm 2000.
10. A Byzantine Fault Tolerant Raft (John Clow, Zhilin Jiang - 2017)
Dựa trên ý tưởng của thuật toán Practical Byzantine Fault Tolerance (PBFT) xây dựng trên nền Paxos, paper trình bày cách cải tiến thuật toán Raft chịu được mô hình lỗi Byzantine.