Paper
- ZooKeeper: Wait-free coordination for Internet-scale systems
- A simple totally ordered broadcast protocol
Giới thiệu
Nhắc tới ZooKeeper, lập trình viên sẽ nhớ ngay tới các thư viện hoặc framework nổi tiếng sử dụng như Kafka; Hadoop. Zookeeper thường được nghĩ tới như là một hierarchical key-value database và có thể dùng cho mục đích leader election / configuration management / … Vậy thật sự Zookeeper cung cấp những chức năng gì?
ZooKeeper là một service cung cấp một tập interface API cơ bản, từ đó lập trình viên có thể dựa vào đó viết tiếp những ứng dụng nâng cao hơn như configuration management; leader election; distributed locking; distributed queue; …. Song song đó, ZooKeeper cần phải đảm bảo vấn đề performance khi có nhiều client query (read + write) tới hệ thống.
Architecture
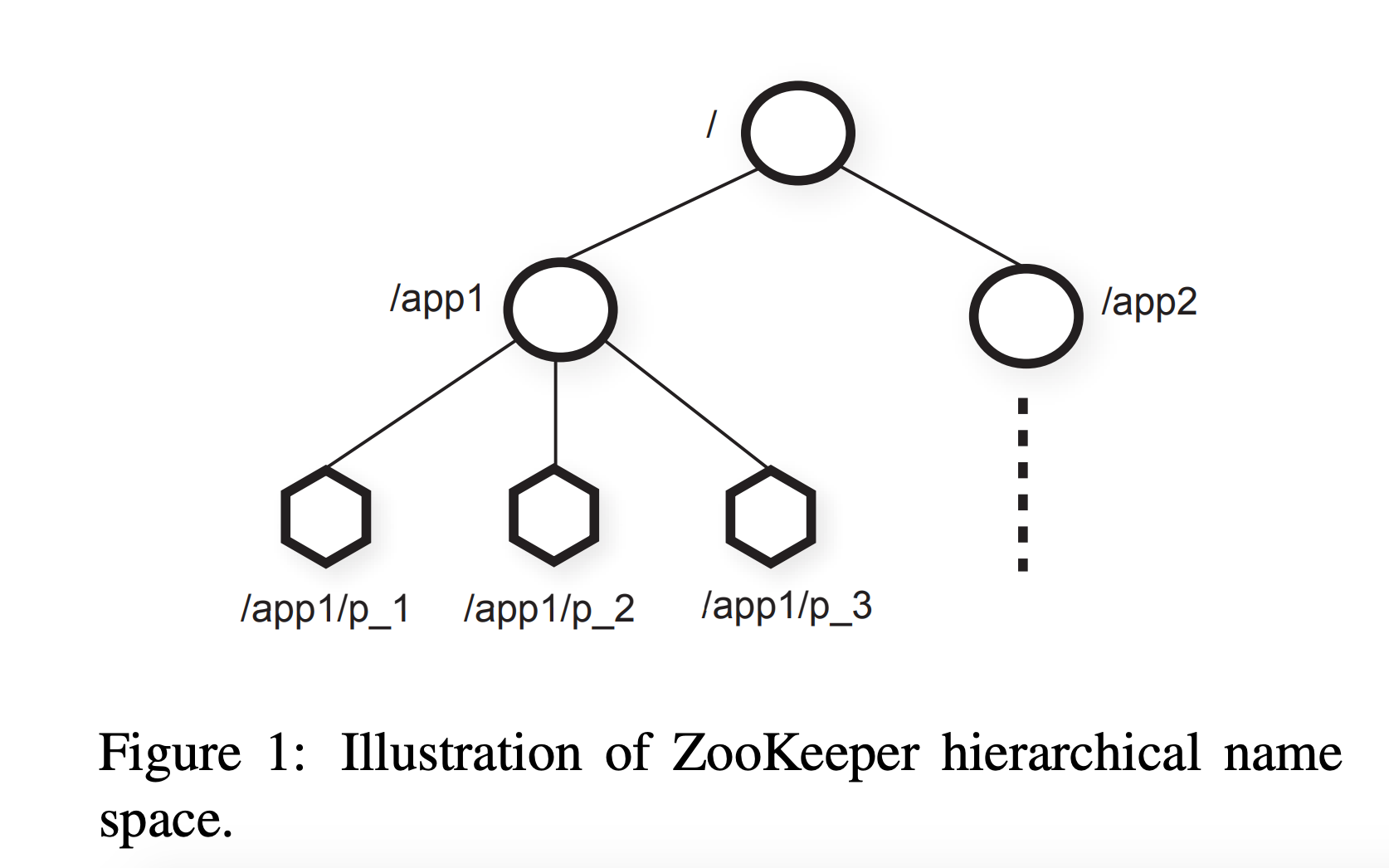
ZooKeeper là một Hierachy key-value database. Các key sẽ được tổ chức theo dạng cây như hình vẽ trên (về mặt logic)
ZNode
- Normal (Persistent)
- Ephemerial: khi một client connect tới ZooKeeper server, sẽ tạo ra một session. Khi client đấy leave → timeout → ephemerial node sẽ bị xóa.
- Sequential: Mỗi node khi tạo ra sẽ có một id định danh duy nhất giữa tất cả thằng con của node cha.
Attribute: Mỗi znode sẽ đính kèm một version
Client API
- create(path, data, flags): Tạo ra một znode với path và data
- delete(path, version): Xóa một znode nếu znode version đó khớp với version gửi đi
- exists(path, watch): trả về true/false tùy thuộc vào tồn tại znode đó có trên server hay không. đồng thời trả về watch (nếu watch là true) để theo dõi sự thay đổi của biến
- getData(path, watch): trả về data + meta-data của znode đấy. Watch tương tự như exist, tuy nhiên có khác biệt là ZooKeeper sẽ không tạo watch nếu znode không tồn tại.
- setData(path, data, version): ghi data vào znode path nếu version khớp với znode hiện tại phía server.
- getChildren(path, watch): trả về tất cả children của path đó.
- sync(path): Chờ cho toàn bộ update cho đến thời điểm truy vấn propagate tới server được đâu (path tại thời điểm paper đang được bỏ qua).
Tất cả các API đều có 2 phiên bản: đồng bộ và bất đồng bộ. Với phiên bản bất đồng bộ, ZooKeeper đảm bảo toàn bộ các callback được gọi đúng theo thứ tự. (xem thêm ở phần Consistency Guarantee ở dưới)
Tất cả các API update (delete/ update) đều kèm theo version number như một cách để xử lí concurrent control.
Question: Khi một tiến trình watch một node, thông tin về watch được lưu ở đâu?
Answer: thông tin về watch được lưu local ở server replica mà client gửi query tới. Nếu replica đó bị crash, client thực hiện lại quá trình đọc/watch ở một replica khác. Do vậy, client phải handle trong code để đảm bảo tính consistency đúng. (Có thể xảy ra trường hợp user back về quá khứ)
Consistency Guarantee
ZooKeeper sử dụng thuật toán ZAB (ZooKeeper Atomic Broadcast) để xử lí . Ta sẽ tìm hiểu rõ hơn ở bài viết khác. Tuy nhiên, toàn bộ thuật toán đảm bảo:
Linearizable writes: Tất cả các request ghi đều phải đi qua node master, và tuân thủ theo linearizability.
FIFO client order: tất cả requests đọc đều tuân theo thứ tự ghi
Nói cách khác, đây là casual consistency. Đây là level consistency cao nhất mà hệ thống có thể tiếp tục hoạt được khi có network partition.
Linearizable
Hệ thống nhìn vào các transaction như trên một node duy nhất. Hay nói cách khác, tồn tại một “total order” của các transaction phù hợp với thời gian thực.
→ Recency guarantee
Dựa vào lịch sử transaction, ta có thể phỏng đoán hệ thống có phải là linearizable không bằng cách vẽ lại lịch sử của các transaction trên cùng một timeline. Nếu tồn tại một cách vẽ phù hợp với lịch sử giao dịch, và không có đồ thị vòng → có thể là linearizable. Trường hợp ngược lại, ta chắc chắn không phải là linearizable.
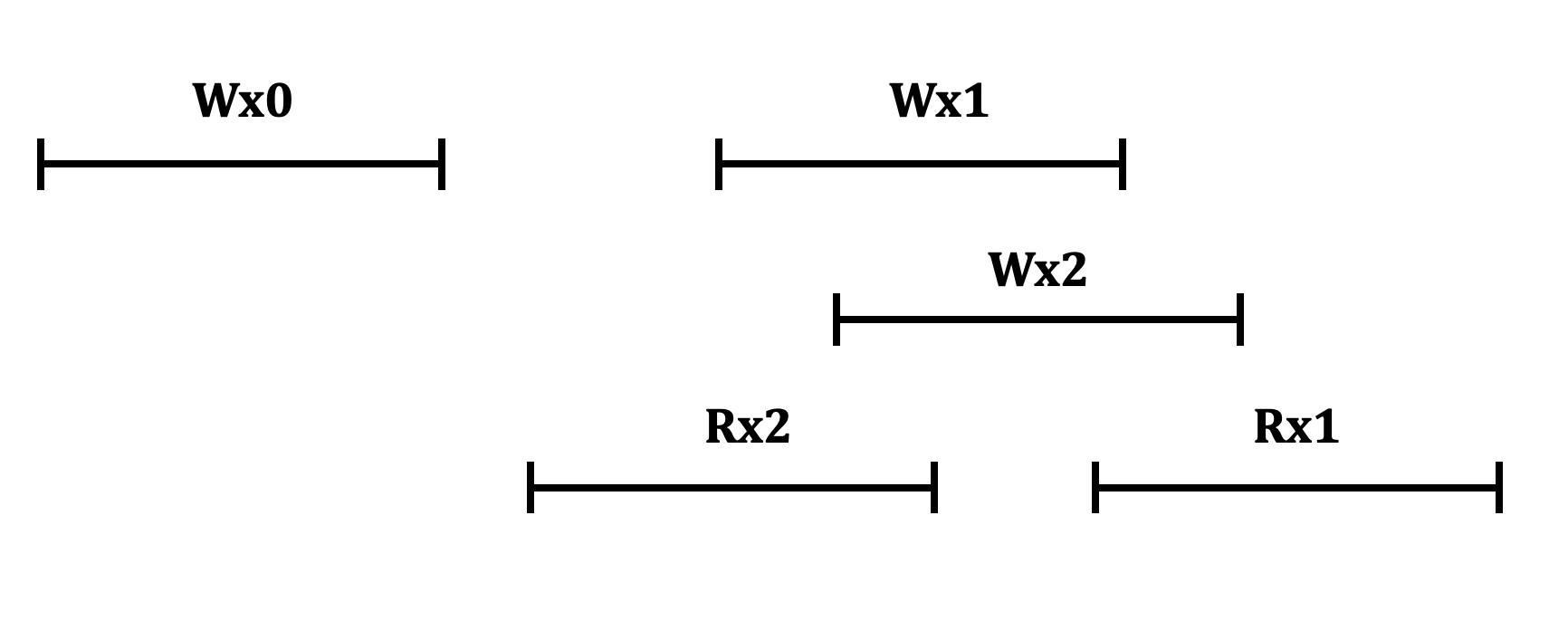
Linearizable: Wx0 → Wx2 → Rx2 → Wx1 → Rx1

Non Linearizable: không tồn tại cách vẽ nào tuyến tính. Ví dụ như: Wx0 → Wx2 → Rx2 (C1) → Wx1 → Rx1 (C1) → Rx1(C2) → Wx2 → Rx2(C2) (cycle).
Non Linearizable: không được stale read.
Question: So với Raft là linearizable cả read và write, Tại sao ZooKeeper lại chọn mô hình consistency này?
Answer: Với các hệ thống ví dụ như Raft; đọc và ghi đều phải đi qua master, sẽ dễ tạo nên hiệu ứng nghẽn cổ chai trong môi trường high load. Việc nâng cấp thêm nhiều máy không giải quyết được vấn đề này, và ngược lại còn làm tệ hơn.
Với cách làm của ZooKeeper: việc ghi thông qua master, còn việc đọc sẽ thông qua các replicas. Do vậy, node master không bị quá tải khi tỉ lệ đọc tăng cao, và ta có thể tạo thêm instance vào trong cluster để tăng read throughput. Chọn việc FIFO cho read consistency phù hợp với mô hình này.
Primitive Building Block
Giải thích
Như ta giải thích ở phần trên, các tập API của ZooKeeper tương đối abstract nhưng đồng thời vì vậy rất linh động để tạo nên những well-defined building block phục vụ cho những hệ thống phân tán lớn khác.
Một số bulding block còn thỏa mãn được thuộc tính wait-free.
Group Membership
Thuật toán
- Khởi tạo ra một znode Zg đại diện cho một group
- Khi một tiến trình muốn join vào group:
- Sẽ tạo ra một ephemeral node thuộc Zg. Đặc tính của ephemeral node là khi tiến trình đấy out khỏi group (heartbeat timeout), ZooKeeper có thể tự động xóa node con đấy ra khỏi group. ID của node con đấy phải unique: có thể được gửi từ client hoặc gán thêm cờ “sequential”
- Đặt watch vào Zg (node cha). Khi bất cứ có node nào thoát khỏi group sẽ được notify → xóa node bị xóa khỏi danh sách dưới local.
Count
while true:
value, v = get_data("count") // replica
if set_data("count", value+1, v) // master
break
end
// sleep(time*2) // avoid many unknown clients waits
end
Simple Lock
Acquire
if create("f", ephemerial=true) return // acquired lock
if exists("f", watch=true)
wait
goto 2
Release
delete("f")
Simple Locks without Herd Effect (hiệu ứng bầy đàn)
Vấn đề của Simple lock: khi toàn bộ các tiến trình lắng nghe vào một key duy nhất: khi key đó được release, toàn bộ các node đều nhấn được event. Khi đó, toàn bộ các tiến trình sẽ đồng thời nhảy vào để dành được lock. Hệ thống sẽ quá tải khi số tiến trình trở nên quá lớn.

Giải pháp: Ta hạn chế việc các tiến trình cùng lắng nghe vào một key duy nhất, do vậy khi một khóa được release, chỉ có tối đa một node nhận được event và giành quyền kiểm soát lock.
Thuật toán:
Func Acquire
n, v=1 = create(prefix + "/lock-", epher|sequential)
while true:
C = getChildren(prefix, false)
if n is lowest znode in C
// acquired lock
return
p = znode in C ordered just before n
if exists(p, true)
wait
// leave out wait. run back to 4
Func Release
Delete(n)
Giải thích
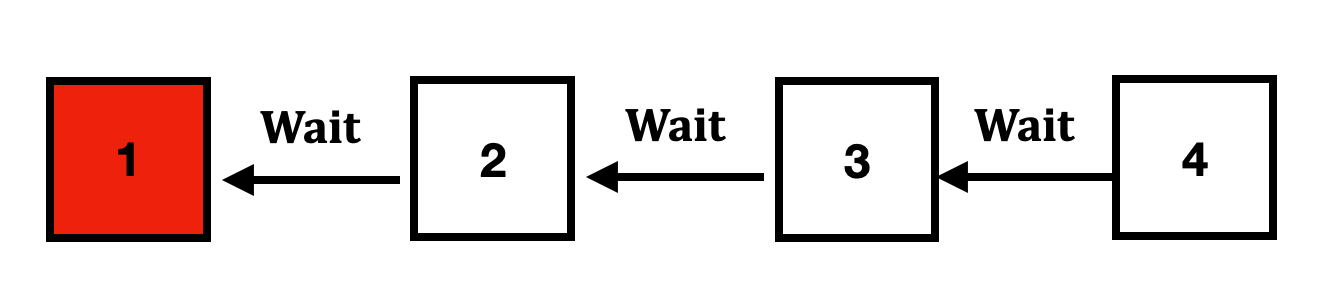
Mỗi node sẽ tạo ra một node con với 2 thuộc tính cùng lúc: ephemerial + sequential trên một tree cha nào đó (prefix) (dòng 2)
Sau đó sẽ gửi tiếp một truy vấn lấy hết toàn bộ node con. (dòng 5)
Sau đó kiểm tra nếu node vừa tạo ra có ID nhỏ nhất trong tất cả các node con: nếu đúng → acquire lock
Nếu không phải, lấy id ngay đằng trước và lắng nghe sự kiện khi node đó thoát ra hệ thống (release lock) (dòng 11 và 12)
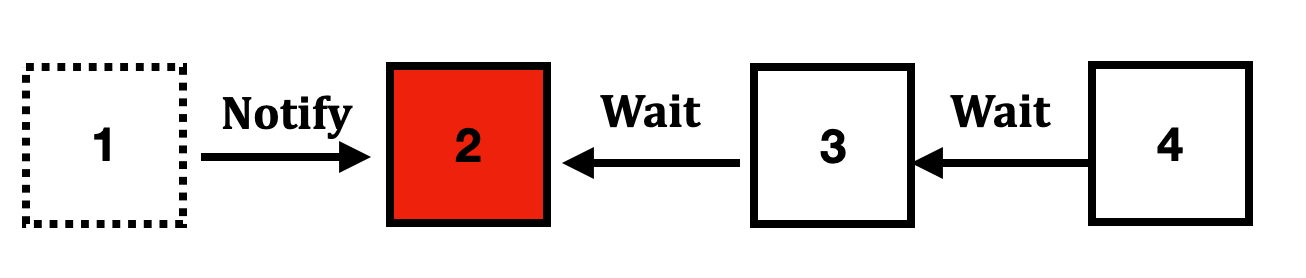
Đến khi node 1 release lock (xóa znode ra khỏi hệ thống), ZooKeeper sẽ notify cho tất cả các client lắng nghe vào node này. Ở đây luôn luôn có duy nhất một node nghe.
Sau đó, node số 2 lại tiếp tục truy vấn lần nữa để chắc chắn mình là node nhỏ nhất. Nếu đúng, acquire lock. (dòng 5)
Read Write Locks
Pseudocode cho write lock
Write Lock
1 n = create(prefix + “/write-”, EPHEMERAL|SEQUENTIAL) 2 C = getChildren(l, false)
3 if n is lowest znode in C (toan bo cay), exit
4 p = znode in C ordered just before n <-- wait for all writes and reads before itself
5 if exists(p, true) wait for event 6 goto 2
Pseudocode cho read lock
Read Lock
1 n = create(prefix + “/read-”, EPHEMERAL|SEQUENTIAL)
2 C = getChildren(l, false)
3 if no write znodes lower than n in C, exit
4 p = write znode in C ordered just before n <-- wait for all writes before itself
5 if exists(p, true) wait for event
6 goto 3
Ta nhận thấy:
WriteLock#3: chờ cho tất cả read lock và write lock pass
ReadLock#5: chờ cho tất cả write lock release
Và nhiều ứng dụng khác: Double Barrier; Leader Election; Configuration Management; …
ZooKeeper Atomic Broadcast (ZAB) Protocol
Tổng quan
zxid: Với mỗi message, leader sẽ assign một unique ID 64 bit. Format zxid: [epoch].[counter]
- part 1: 32 bit. epoch number. tương tự term trong Raft. tăng dần đều 1 đơn vị khi chuyển qua 1 leader mới
- part 2: 32 bit. mỗi khi epoch number chuyển qua giá trị mới, counter sẽ reset về 0.
→ Total Ordering cho toàn bộ message trong hệ thống. Chính nhờ total ordering, ZooKeeper có thể maintain được FIFO read trên các replica node. (Giai thich tiep phan sau …)
Ví dụ, thứ tự zxid có thể là: 1.1; 1.2; 1.3; 2.1; 2.2; 2.3; 2.4; 3.1; 3.2; 3.3; 3.4
FIFO Channel: protocol sử dụng giao thức TCP và đảm bảo thứ tự gửi nhận của các request → không cần quan tâm đến message ordering.
2PC (2-phase commit protocol): ZAB sử dụng 2-phase commit protocol cho việc broadcast dữ liệu.

Leader Election
- Khi xảy ra timeout trên node leader, sẽ trigger sự kiện leader election
- ZAB sẽ bầu chọn ra node có zxid cao nhất trong hệ thống (tại sao: sẽ giải thích ở phần sau). ZAB không nêu rõ cụ thể bước này.
Recovery
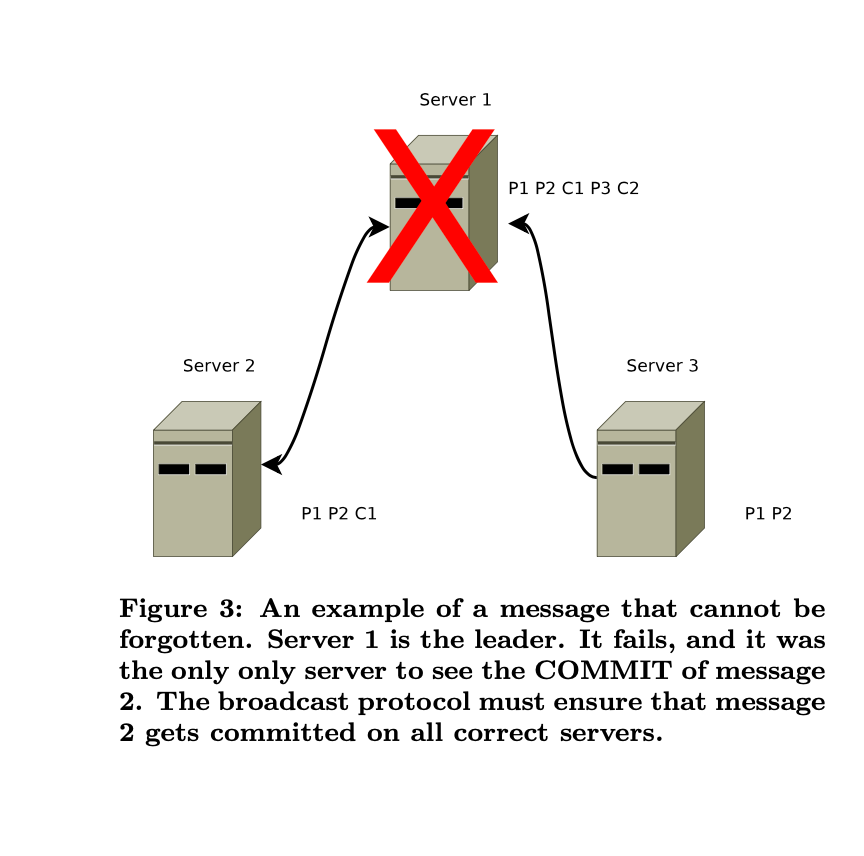
Xét ở ngữ cảnh server 1 là leader:
- server 1 đã replicate P1 và P2 qua server 3 và P1 P2 C1 qua Server 2.
- Ta thấy P2 đã xuất hiện quá bán, do vậy server 1 sẽ:
- commit messagee (apply vào FSM)
- trả kết quả về cho client
- gửi gói tin COMMIT ra toàn mạng (FAIL)
→ Ở đây, ta thấy hành vi tương đối giống Raft.
Tuy nhiên, TRƯỚC KHI gửi gói tin COMMIT, server 1 bị crash. Ta thấy rõ ràng server 1 đã commit C1 và đồng thời client cũng đã thấy gói tin C1, như vậy gói tin C1 buộc phải có mặt ở leader tiếp theo (dù thông tin được commmit chưa gửi đi).
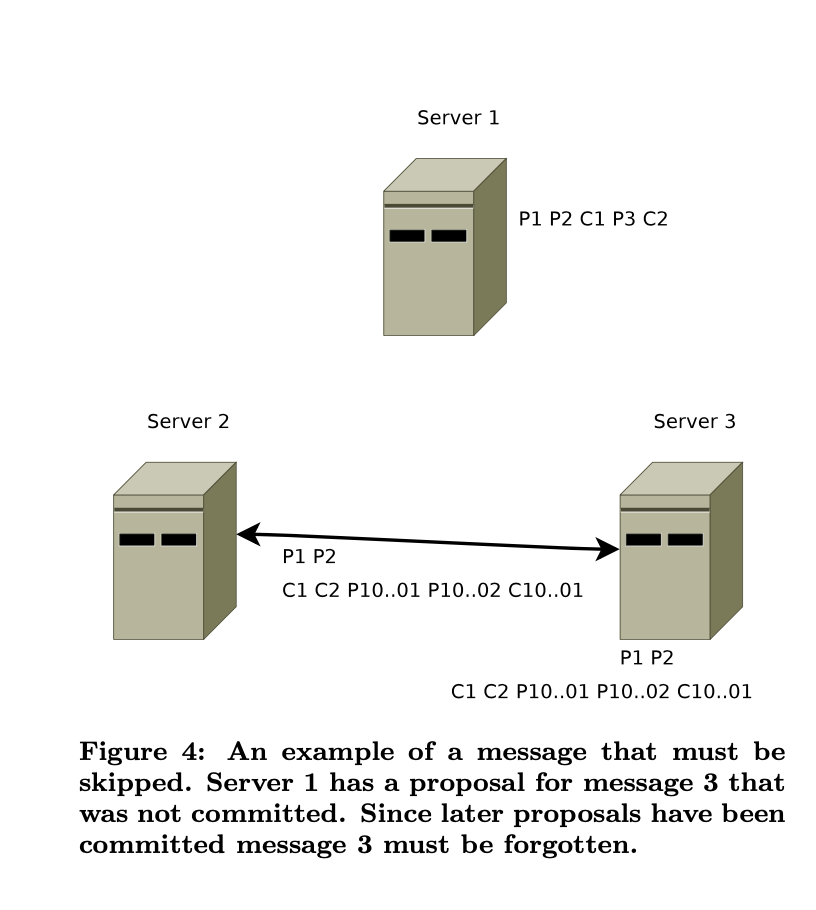
Cách ZooKeeper xử lí:
- Chọn ra server replica có zxid lớn nhất. ở đây là server 2 với C1. (Gợi nhớ: message trong mạng là total ordering)
- Khi trở thành leader thành công, leader sẽ bắt đầu replica các gói tin còn thiếu ra toàn mạng. các node chưa bắt kịp gói tin mới nhất sẽ không được nhận các gói tin mới hơn đến leader này.
Trường hợp leader cũ (ở đây là server 1) recover lại:
- server 1 nếu vẫn nghĩ rằng mình là leader, broadcast gói tin → sẽ bị từ chối do các node khác đã thấy được message ở epoch cao hơn.
- server 1 trở thành replicas, và bắt đầu quá trình replicate các data còn thiếu. Với các data dư, server 1 sẽ drop. Tron hình minh họa, server 3 sẽ drop P3 và C2.
Nhận xét khác biệt trong leader election giữa Paxos / Raft và ZAB:
- Raft: đưa ra chiến thuật “thông minh” nhất: tìm ra được node chứa latest log mà đã replicate qua quá bán.
- Multi-Paxos: “đần” hơn; chỉ hoàn toàn dựa vào node nào raise thành leader (điều kiện: round phải lớn hơn hiện tai) thành leader. Do vậy phải giải quyết bài toán synchronise log giữa leader và replicas.
- ZAB: chiến thuật dễ nhất, cứ việc chọn node có zxid lớn nhất (cho dù các message đó có thể chưa được replica qua quá bán các node).
Câu hỏi: Khác biệt nào về leader election giữa Raft và ZAB?
Trả lời:
ZAB: zxid được build bằng cách [epoch].[counter] (với counter reset về 0 khi qua epoch mới) thì leader condition là chọn zxid lớn nhất (so sánh epoch, sau đó so sánh counter)
Raft: phát biểu up-to-date condition:
If the logs have last entries with different terms, then the log with the later term is more up-to-date.
If the logs end with the same term, then whichever log is longer is more up-to-date
Nếu ta đặt log entry ID = [term].[index] , thì phát biểu này lại rất giống với thằng ZAB.
Như vậy, tuy. cách phát biểu khác nhau, nhưng về bản chất rất giống nhau trong leader election.
ZooKeeper applications
Fetching Service
- Giải thích: search engine. có một node master để quản lí toàn bộ process
- Application: Sử dụng ZooKeeper cho recovering master / leader election / configuration metadata
Yahoo! Message Broker
- Giới thiệu: là một hệ thống distributed publish-subscribe
- Ứng dụng: Sử dụng ZooKeeper để quản lí cấu hình / failure detection / group membership
References: