Multi-decree Paxos: cách xây dựng thuật toán đồng thuận trên một chuỗi giá trị dựa trên Single-decree Paxos, cùng chứng minh định lí.
Paper
Giới thiệu
Thuật toán Single-decree Paxos, như đã trình bày, chỉ áp dụng để đồng thuận trên cùng một giá trị. Các bài toán thực tế cần đồng thuận trên đa giá trị, và đó là ý tưởng chính cho Multi-decree Paxos.
Ý tưởng thuật toán
Tư tưởng chính: ta sẽ chạy nhiều instance Single-decree Paxos, mỗi instance đồng thuận trên một giá trị ta mong muốn. Tuy nhiên, ta cần xử lí bài toán: làm sao để các node đồng thuận trên cùng một chuỗi giá trị.
State Machine
Một cách mô hình hóa đơn giản bài toán này như sau: client sẽ issues command tới một server. Server có thể được thiết kế như một state machine, và do vậy, deterministic. Server sẽ lần lượt thực thi client command theo một sequence.
Server này trong trường hợp bị crash, ta muốn hệ thống vẫn tiếp tục hoạt động. Do vậy, đây sẽ là một tập các server thực thi state machine độc lập nhau. Vì state machine chúng ta xây dựng là tất định (deterministic): các server sẽ có output giống nhau nếu thực thi một chuỗi các input giống nhau.
Thuật toán
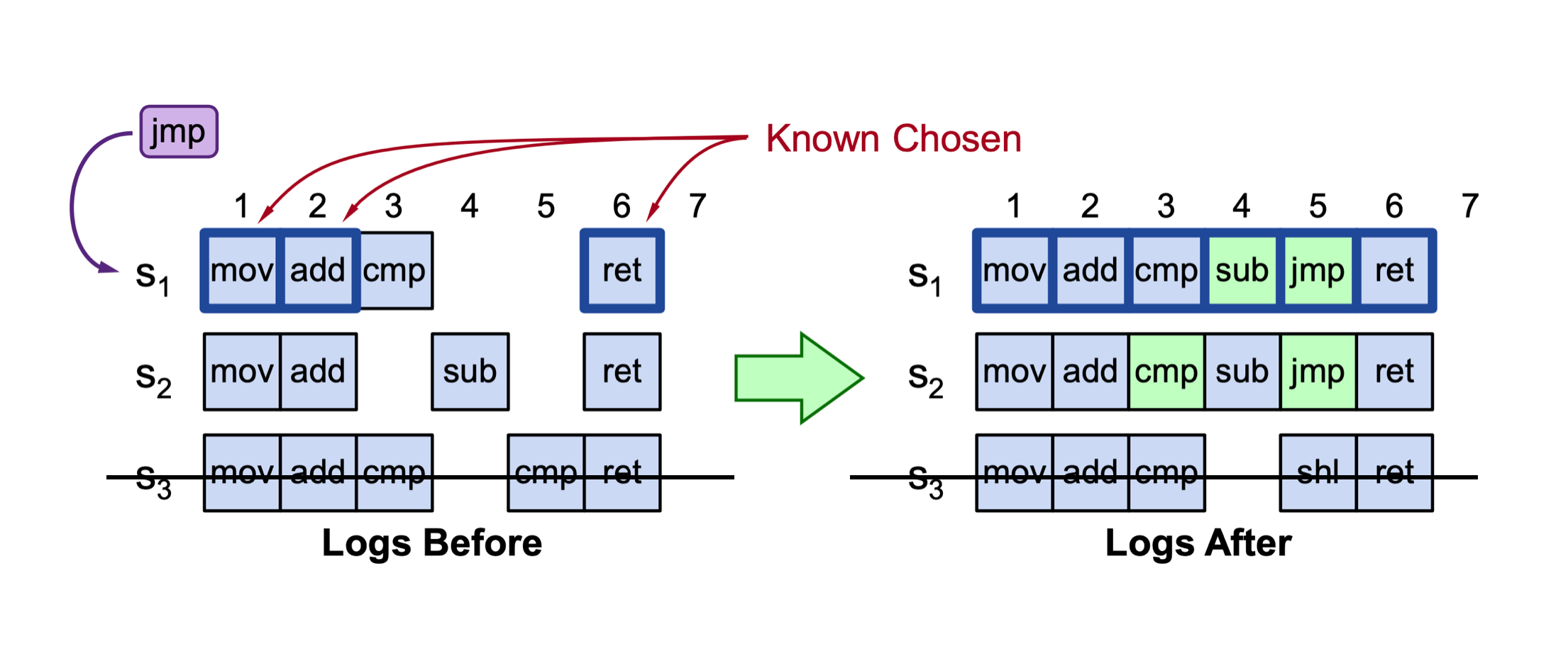
Ta có thể dựa trên Single-decree Paxos: Với một client command, ta sẽ chạy một single-decree Paxos instance. Từ đó, bài toán tiếp theo là làm sao để các node đồng thuận trên cùng một chuỗi các Paxos instance.
- Tìm index đầu tiên chưa được có log entry
- Nếu tồn tại trên chính nó: kết thúc
- Tìm kiếm trên các node khác: nếu tồn tại → replicate về local. Chọn log entry có epoch cao nhất.
- Sau khi tìm được vị trí đầu tiên chưa tồn tại log entry: insert client command. sau đó chạy môt Paxos instance tại index đấy.
Như vậy, ta thấy:
- Có thể thực thi client command song song
- Tuy nhiên, chỉ có thể apply commands vào state machine theo đúng thứ tự. Cụ thể: khi và chỉ khi log entry ở vị trí thứ Nth đã được replicate quá bán → được commit. Và khi và chi khi được commit vào FSM, node mới được quyền commit tiếp ở (N+1)th index.
Nhược điểm
-
Conflict: dễ xảy ra conflict khi nhiều proposer hoạt động cùng lúc.
-
Theo thuật toán single-decree Paxos, mỗ instance Paxos cần chạy 2 around, ảnh hưởng tới performance
a. Prepare: block các proposal cũ + học các giá trị được chọn trước đó (nếu có)
b. Accept: đồng thuận trên giá trị v
Leader
Ta thấy lí do quan trọng cần phải có gói tin Prepare là:
- Chặn các proposal cũ
- Đồng thời tìm ra các possible values.
Một suy nghĩ tự nhiên để giải quyết bài toán trên, ta sẽ thêm vào một role mới: leader. Khi bắt đầu, leader sẽ được bầu ra, và do vậy không cần gói tin Prepare nữa.
Paper không nói rõ cách bầu chọn leader, nhưng propose một số idea như:
- leader sẽ được chọn theo thứ tự bản chữ cái
- “người giàu nhất”: có thể hiểu như là node đã observe được nhiều message trong hệ thống.
- “độ honest”
Lí do: việc chọn theo tiêu chí nào không thật sự quan trọng, vì có thể tồn tại hơn 1 leader.
Protocol
Standard Operation
Bước 1: Trong điều kiện bình thường, một server sẽ được bầu làm leader. Client sẽ bắt đầu gửi command tới server này.
Bước 2: Leader sẽ chọn index cho command này. Ví dụ: nếu leader thấy command này nên giữ index là 10 (do đã có 9 commands được issue trước đấy), leader sẽ bắt đầu đánh dấu command này là 10 - và bắt đầu 10th Paxos instance.
Bước 3: Leader sẽ gửi propose(message) cho toàn bộ các acceptor cùng các thông tin cần thiết như nội dung message, ballot id hiện tại.
Bước 4: các acceptor sẽ kiểm tra ballot id của message: Nếu ballot id này nhỏ hơn ballot id đã được observe thì sẽ reject, và trả về cho leader giá trị ballot id này. Ngược lại, sẽ đồng ý, và ghi xuống log.
Bước 5: Leader khi nhận được response từ các request vote: Nếu tồn tại ít nhất một request reject vì có ballot id lớn hơn, leader cập nhật ballot id này và trở về lại trạng thái follower. Ngược lại, message tại index này được approve.
So sánh với Raft:
- Điểm giống: hầu như toàn bộ quá trình này giống với Log replication bên Raft.
- Điểm khác: Raft sẽ replicate toàn bộ các log sequence mà chưa replicate tới một node bất kì. Multi-decree Paxos đặc tả ban đầu sẽ gửi các sequence độc lập nhau. Do vậy, khi mà một log entry được replicate thành công qua quá bán các acceptor, ta vẫn phải chờ cho các message ở giữa replicate thành công. Ví dụ: leader đã replicate thành công các log entry từ 1 -> 10 và từ 15 → 20. Các log entry từ 1 → 10 có thể an toàn cập nhật. Tuy nhiên, các log entry từ 15 → 20 cần phải chờ cho các log entry từ 11 → 14 replicate thành công.
Leader Election
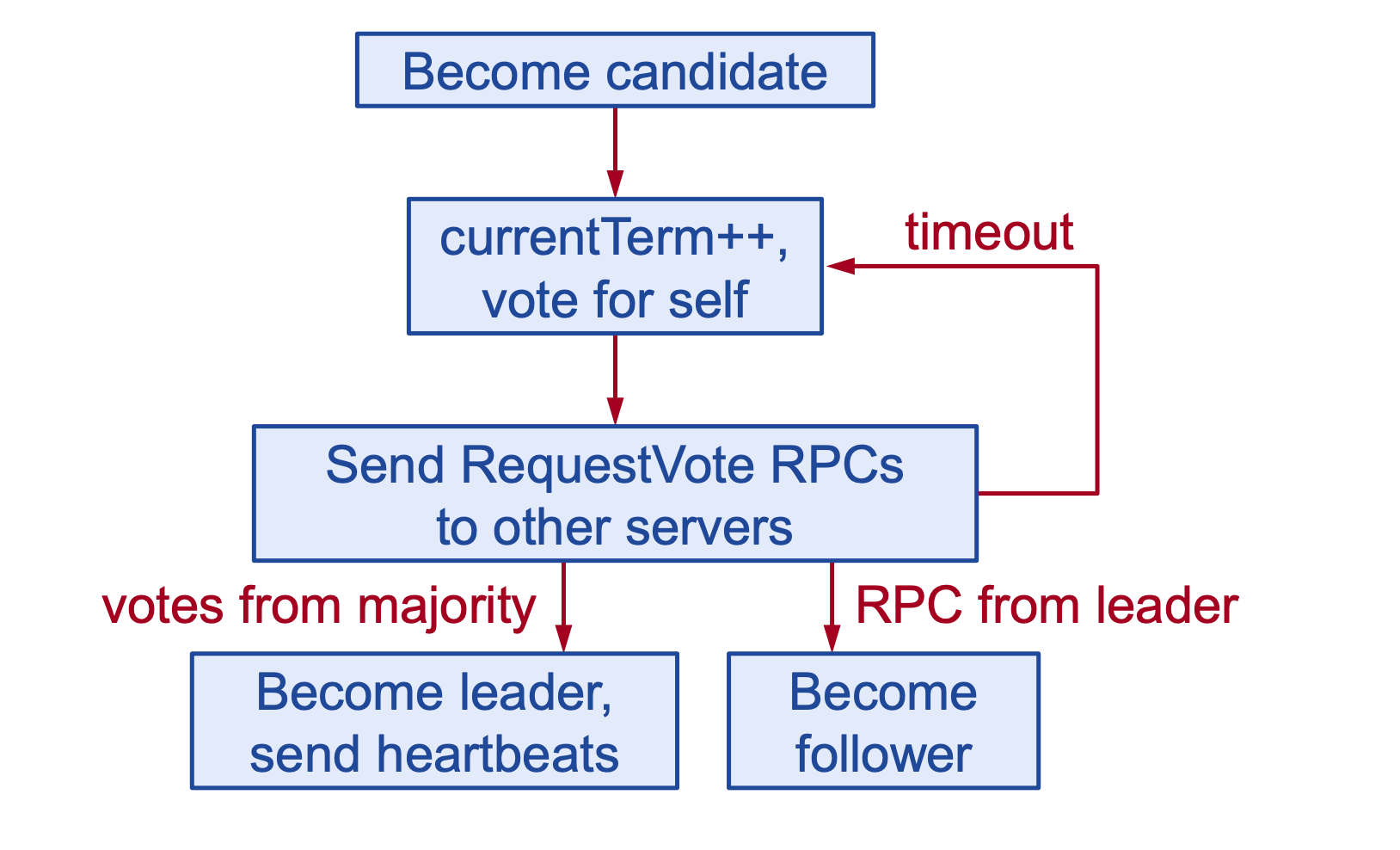
bầu chọn leader trong Raft
Bước 1 :Khi leader hiện tại bị crash (hoặc một node bất kì không thể access được), các node sẽ bắt đầu quá trình leader election.
- Node muốn được bầu làm leader - gọi là candidate, sẽ chọn ra một ballot id unique, và lớn hơn những ballot id từng được observe trên chính node đó. Thuật ngữ ballot tương tự với term bên Raft.
- Candidate đồng thời gửi latest commit id (được dùng ở bước 2)
Bước 2: Ở các node follower, khi nhận được request vote:
sẽ kiểm tra ballot id của candidate. Nếu ballot id này nhỏ hơn ballot id đã được observe thì sẽ reject request vote, và trả về cho candidate giá trị ballot id này. Ngược lại, sẽ đồng ý, và đồng thời sẽ cập nhật ballot id từ candidate.
Trả về cho candidate toàn bộ log từ sau candidate latest commit id.
Bước 3 :Candidate khi nhận được response từ các request vote:
Nếu tồn tại ít nhất một request reject vì có ballot id lớn hơn, candidate cập nhật epoch này và trở về lại trạng thái follower.
Ngược lại, Khi nhận được quá bán các approvals, node đấy sẽ trở thành leader. Khi đấy, leader sẽ bắt đầu merge các log từ các follower về local
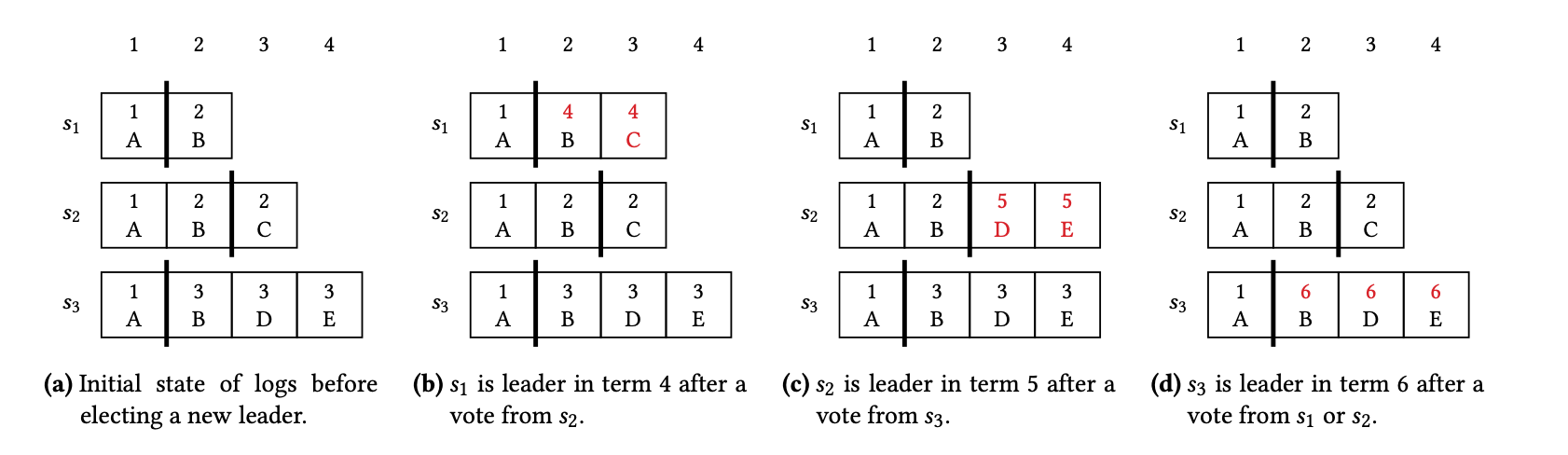
Hình a: trạng thái hiện tại. Hình b, c, d: nếu từ a, S1, S2, S3 trở thành leader tương ứng.
| Hình | Follower | Candidate / Leader |
|---|---|---|
|
Các node sẽ gửi về log entry từ 2th (do latest commit index của S1 là 1) S2 gửi về - (index=2, ballot_id=2, message=B) - (index=3, ballot_id=2, message=C) |
- merge index 2th: data la B - ballot id mới là 4 - merge index 3th: data là C - ballot id mới là 4 |
|
|
Các node sẽ gửi về log entry từ 3th (do latest commit index của S2 là 2) S3 gửi về - (index=3, ballot_id=3, message=D) - (index=4, ballot_id=3, message=E) |
- merge index 3th: có conflict giữa (2, C) và (3, D). Ta chọn D, vì entry này có ballot id lớn hơn (3 vs 2). ballot id mới là 5. - merge index 4th: data là E (S2 chưa có entry tại 4th) - ballot id mới là 5 |
|
|
Các node sẽ gửi về log entry từ 2th (do latest commit index của S3 là 1) S1 gửi về: - (index=2, ballot_id=2, message=B) S2 gửi về: - (index=2, ballot_id=2, message=B) - (index=3, ballot_id=5, message=D) - (index=4, ballot_id=5, message=E) |
- merge index 2th: chọn (ballot=2, data=B ) - ballot id mới là 6 - merge index 3th: chọn (ballot=5, data=D) - ballot id mới là 6 - merge index 4th: chọn (ballot=5, data=E) - ballot id mới là 6 |
So sánh với Raft:
Điểm giống: quy trình vote hầu như giống nhau: detect một node crash, bầu bản thân lên làm leader ở một term / ballot id mới. Leader sẽ là node có term / ballot id lớn nhất.
Điểm khác:
- Term / ballot id: ở Raft, sẽ có tình trạng các node candidate cùng propose một term, tuy nhiên, ở Paxos, ballot id được propose luôn là unique.
- Leader election condition: Paxos hầu như không có bất kì điều kiện gì để một node có thể trở thành leader (trừ việc ballot id phải là lớn nhất mà các acceptor đã từng observe). Ở Raft, một node muốn trở thành leader phải thỏa mãn điều kiện up-to-date. Điều kiện này cũng làm nên sự khác biệt lớn giữa Raft và Paxos sau khi một leader bầu chọn thành công. Raft cho rằng, điều kiện này làm cho thuật toán Raft có thể dễ hiểu hơn. Tuy nhiên, điều này không hẳn là đúng.
Toàn bộ khác biệt giữa Raft và multi-decree Paxos sẽ được làm rõ ở phần sau - khi phân tích các paper liên quan.
Điều kiện up-to-date trong thuật toán Raft:
candidate’s last entry term > follower’s last entry term
OR
candidate’s last entry term == follower’s last entry term AND candidate’s log length > follower’s log length
Log replication sau quá trình bầu chọn
Bước 1: Trong quá trình vote, candidate đã thu thập toàn bộ log sequences từ các node khác.
Bước 2: Sau khi trở thành leader, node sẽ bắt đầu tổng hợp tất cả các log entry từ các node khác thành một chuỗi hoàn chỉnh (table trên)
- Nếu nhiều hơn một log entry từ các acceptor tại một index: chọn log entry có ballot id cao nhất
- Nếu không có log entry tại các index ở giữa: leader tạo ra null-entry tại các index đó
Các log entry được append vào local sẽ có ballot id là giá trị ballot ở hiện tại (a.k.a: lớn nhất mà leader từng observe). Sau đấy, leader sẽ đồng bộ log sequence này ra toàn bộ các acceptor.
Ví dụ một trường hợp các null-entry:
|
S1: (1, 1) | (1, 2) (1, 3) S2: (1, 1) | … (1, 3) S3: (1, 1) | |
S1: (1, 1) | (1, 2) (1, 3) S2: (1, 1) | (1, 3) S3: (1, 1) | (2, null) (2, 3) |
S1: (1, 1) | (2, null) (2, 3) S2: (1, 1) | (1, 3) S3: (1, 1) | (2, null) (2, 3) |
| S1 là leader ở epoch t = 1 | S3 là leader ở epoch t = 2, được bầu bởi S2 | S1 join trở lại, đồng bộ log |
Các bài toán khác cần được giải quyết:
- Đồng bộ log sequence: việc gửi nhận toàn bộ log là rất lớn, và mất thời gian
- Các proposal được gửi song song, và độc lập
Nhận xét về paper
Điểm mạnh
- Trình bày theo dạng high level view, không có ràng buộc vào một implement cục thể. Do vậy, có thể thấy được toàn cảnh bài toán và hướng giải quyết. Đồng thời, việc trình bày giải pháp nhưng không đi sâu vào cách implement cụ thể giúp ta mở ra các cách implement khác nhau phụ thuộc vào nhu cầu hệ thống.
Điểm yếu:
- So với Raft, paper về Paxos thuộc dạng non-operational: có khoảng cách lớn từ việc hiểu thuật toán đến lúc có thể implement một hệ thống tương đối tốt. Ví dụ một số câu hỏi về implement như: làm sao để leader và follower có thể catchup log một cách hiệu quả (thay vì gửi hết toàn bộ log qua các server).
- Chưa đề cập nhiều đến các nhu cầu hiện đại, ví dụ: configuration change; client processing; …
Chứng minh
Ta dựa trên paper về Raft để chứng minh 2 định lí sau:
- Leader Completeness
- State Machine Safety
Đinh lí 1: Leader Completeness
Phát biểu:
Nếu một log entry đã được commit trong một term bất kì, thì log entry đó sẽ có mặt trong mọi log của mọi leader khác ở các term khác cao hơn.
Giải thích
- Một log entry bao gồm 3 thuộc tính: data + term + index. Một log entry được commit sẽ được update vào FSM (Finate State Machine).
- Định lí này đảm bảo trong mọi trường hợp, khi một log entry đã được update vào FSM ở thứ tự cho trước là K, thì ở bất kì leader nào khác (trong các term khác cao hơn), log entry đấy cũng sẽ được update ở thứ tự là K, với K = 1,2,3, … n (chứng minh ở định lí sau)
- Nói cách khác, định lí đảm bảo các log entry sẽ được update lên FSM ở toàn bộ các node theo đúng một thứ tự duy nhất.
Chứng minh
Ta sẽ dựa theo cách chứng minh thuật toán Raft.
Giả sử một leader ở term T1 commit một log entry M index là mth, nhưng log entry đó không được lưu trữ lại ở một leader nào đó ở term tương lai. Không mất tính tổng quát, giả sử term T2 là term nhỏ nhất (T2 > T1) mà leader tại term đó không có lưu trữ log entry đấy.
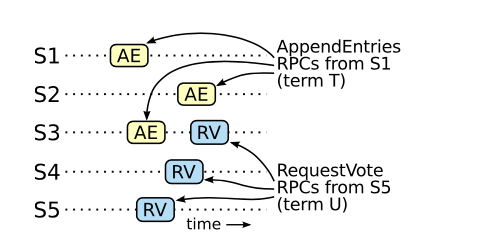
Chứng minh ý 1: Tồn tại một node S3 mà nhận được AppendEntries từ T1 và RequestVote từ T2 theo thứ tự tương ứng như hình vẽ trên
- Vì log entry M đã được commit → phải có quá bán node trong hệ thống nhận được gói tin AppendEntries từ leader T1 về log entry M
- Vì leader term T2 được bầu chọn → phải có quá bán node trong hệ thống nhận được gói tin RequestVote từ leader T2
→ Từ 2 ý trên, ta thấy phải tồn tại ít nhất một node mà đã accept gói tin AppendEntries và RequestVote từ leader T1 và T2 tương ứng, như trong hình là S3. Ở ý này, ta thấy mục đích của việc quá bán trong việc voting và gửi AppendEntries.
→ Gói tin AppendEntries phải đến trước gói tin RequestVote ở S3. Nếu ngược lại, S3 nhận được RequestVote (term T2) → AppendEntries (term T1), S3 sẽ reject gói tin AppendEntries vì T1 < T2 (vô lí).
→ Tồn tại một node S3 mà nhận được AppendEntries từ T1 và RequestVote từ T2 theo thứ tự tương ứng (dpcm)
Chứng minh ý 2: Không thể xảy ra trường hợp trên
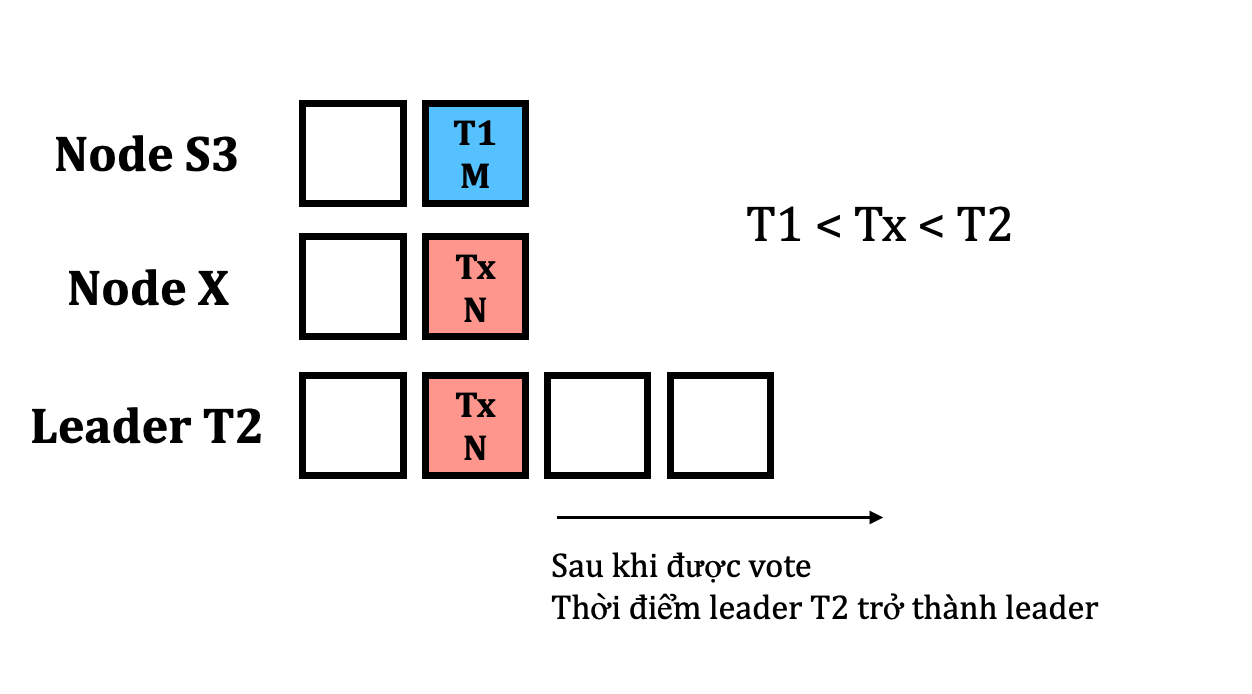
Gọi leader ở term T2 là S. Dựa vào kết quả trên, S đã observe được log entry M ở index mth trong giai đoạn leader election, tuy nhiên lại reject log entry này (lí do: không xuất hiện ở term T2 sau này, theo giả thuyết phản chứng)
Do vậy, tồn tại một gói tin khác ở index mth có term lớn hơn term của M, gọi là Tx. với T1 < Tx < T2 (1)
Nhưng theo giả thuyết ban đầu, T2 là term nhỏ nhất (T2 > T1) mà mà leader tại term đó không có lưu trữ log entry M → với mọi term Tx mà T1 < Tx < T2, một node nếu chứa log lại index mth, thì log đấy phải là M. (2)
Từ (1) và (2) → mâu thuẫn. Từ đó, ta thấy một message khi đã commit ở một node bất kì ở term T, sẽ luôn xuất hiện ở mọi node khác mà có term > T.
Đinh lí 2: State Machine Safety Property
Phát biểu
if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
Giải thích
Nếu một server đã apply một log entry vào State machine, không tồn tại server nào apply một log entry khác ở cùng một index.
Nói cách khác, ở một node bất kì:
- Nếu node đó có term < T, node đấy sẽ chưa được apply log entry tại vị trí T
- Nếu node đó có term >= T, tại vị trí T, node đấy sẽ apply cùng log entry giống với mọi server khác.
Chứng minh
Ta có thể chứng minh phản chứng như sau:
- Giả sử tồn tại một follower mà có index tại K khác với bất kì một node nào có index tại K những đã commit lên FSM → leader truyền cho node mà index tại K cũng phải có giá trị khác.
- Dựa vào định lí Leader Completeness, tất cả các leader của các term sau đó đều phải lưu trữ các log entry tương tự nhau → vô lí.
- Do vậy, follower có index tại K phải chung giá trị với các node khác.
- Do việc apply lên FSM diễn ra tuần tự theo index=0,1,2,… → dẫn đến định lí State Machine Safety Property