So sánh các thuật toán đồng thuận: Raft; Paxos; ViewStamp Replication; ZAB (ZooKeeper Atomic Broadcast). Bài viết cũng đồng thời nêu ra cách để chuyển đổi một implementation từ Paxos sang Raft, từ đấy ta có thể ứng dụng các tối ưu Từ Paxos qua Raft.
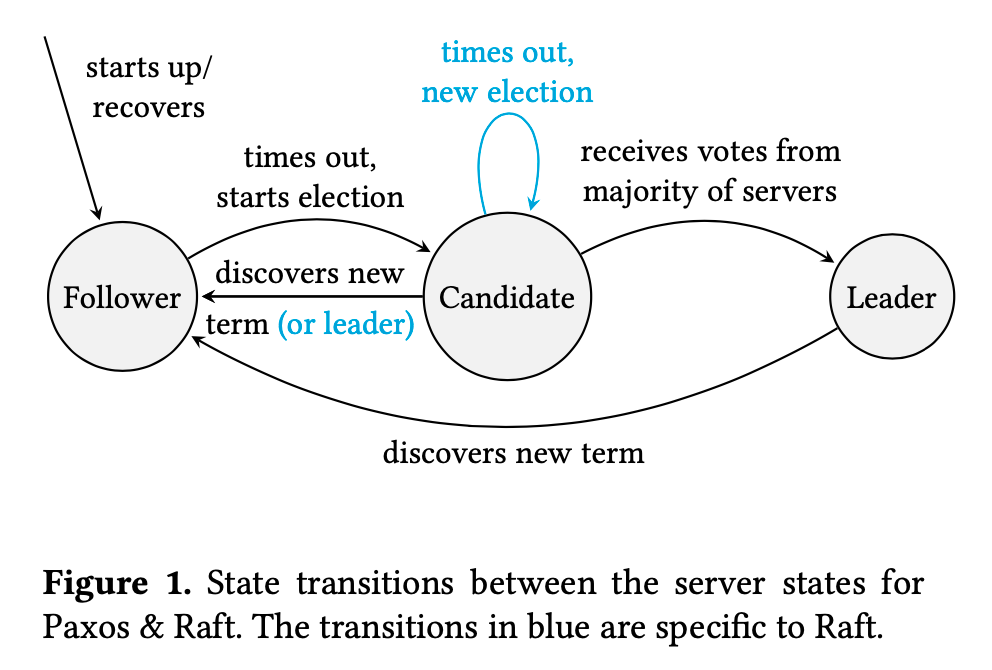
Raft vs Paxos
Paper Paxos vs Raft: Have we reached consensus on distributed consensus?
Giới thiệu
Nghiên cứu về đồng thuận (consensus) là trọng tâm của lĩnh vực hệ thống phân tán. Thuật toán đồng thuận Paxos xuất bản năm 1989 trở thành thuật toán chính trong nhiều hệ thống (Google Spanner; Google Chubby; Apache ZooKeeper). Tuy nhiên, Paxos nổi tiếng vì sự khó hiểu ngay cả trong cộng đồng học thuật. Paper về thuật toán Raft xuất bản năm 2012 là một bước đột phá bởi tính dễ hiểu, và tập trung hơn về khía cạnh engineering trong việc trình bày hướng giải quyết. Các hệ thống phân tán lớn ra đời sau này (etcd; CockroachDB; TiDB; …) sử dụng Raft để giải quyết bài toán đồng thuận hoặc replicate data giữa các máy tính trong mạng.
Tuy nhiên, liệu có sự khác biệt lớn nào giữa 2 thuật toán đồng thuận này không? Việc hiểu rõ sự khác biệt cũng rất quan trọng:
- Đánh giá chi tiết vể performance
- Apply những optimisation từ Paxos (đã được phát triển qua rất nhiều năm) qua Raft.
Ánh xạ khái niệm
| Raft | Paxos | |
|---|---|---|
| Leader Election | RequestVote | Phase1A |
| ReceiveVote | Phase1B | |
| Log Replication | AppendEntries |
- Phase2A - Phase2B |
| Technical Keywords | Term | Ballot |
Implementation

RequestVote

Khác biệt về RequestVote giữa 2 thuật toán phản ánh sự khác biệt về leader election.
Raft: Một node muốn trở thành leader khi node đấy phải có log up-to-date. Mà ta thấy điều kiện up-to-date của Raft là:
candidate’s last entry term > follower’s last entry term
OR
candidate’s last entry term == follower’s last entry term AND candidate’s log length > follower’s log length
Do vậy, argument phải chứa tất cả các tham số trong điều kiện trên.
Implementation: Implementation cho phía follower khi nhận được RequestVote phản ánh điều kiện up-to-date.
Paxos Ngược lại, điều kiện để trở thành leader của Paxos rất đơn giản: ngoại trừ việc term phải lớn nhất (tương tự Paxos), tất cả các node đều đồng ý cho một node trở thành leader.
Do vậy, khác với Raft - một node sau khi trở thành leader thì nghiễm nhiên log trên node đấy là latest. Leader ở Paxos không đảm bảo tính chất này. Do vậy, ở quá trình leader election, candidate buộc phải lấy thông tin về log của tất cả node follower. Nếu candidate trở thành leader, candidate sẽ synchornize log đấy ngược về local.
Rules for candidate

Rule for candiate sẽ có 2 khác biệt:
- Cách chọn term
- Cách xử lí response từ RequestVote
Raft
Ở Raft, một candidate sẽ increase term hiện tại lên 1 và bắt đầu quá trình bầu chọn.
Khi nhận được quá bán response success từ RequestVote, candidate sẽ trở thành leader và không cần xử lí gì thêm (do log đã up-to-date)
Paxos Ở Paxos, cách một candidate lấy term tiếp theo dựa trên hàm module: server id % total node. Cách này dựa trên single-decree và multi-decree Paxos.
Khác với Raft, điều kiện leader election ở Paxos rất đơn giản, do vậy, khi một node từ candidate khi trở thành leader, node đấy không đảm bảo là log ở local là latest. Do vậy, trước khi leader mới được bầu bắt đầu chính thức hoạt động, node phải đồng bộ các log entry từ các log khác về phía mình.
Internal State
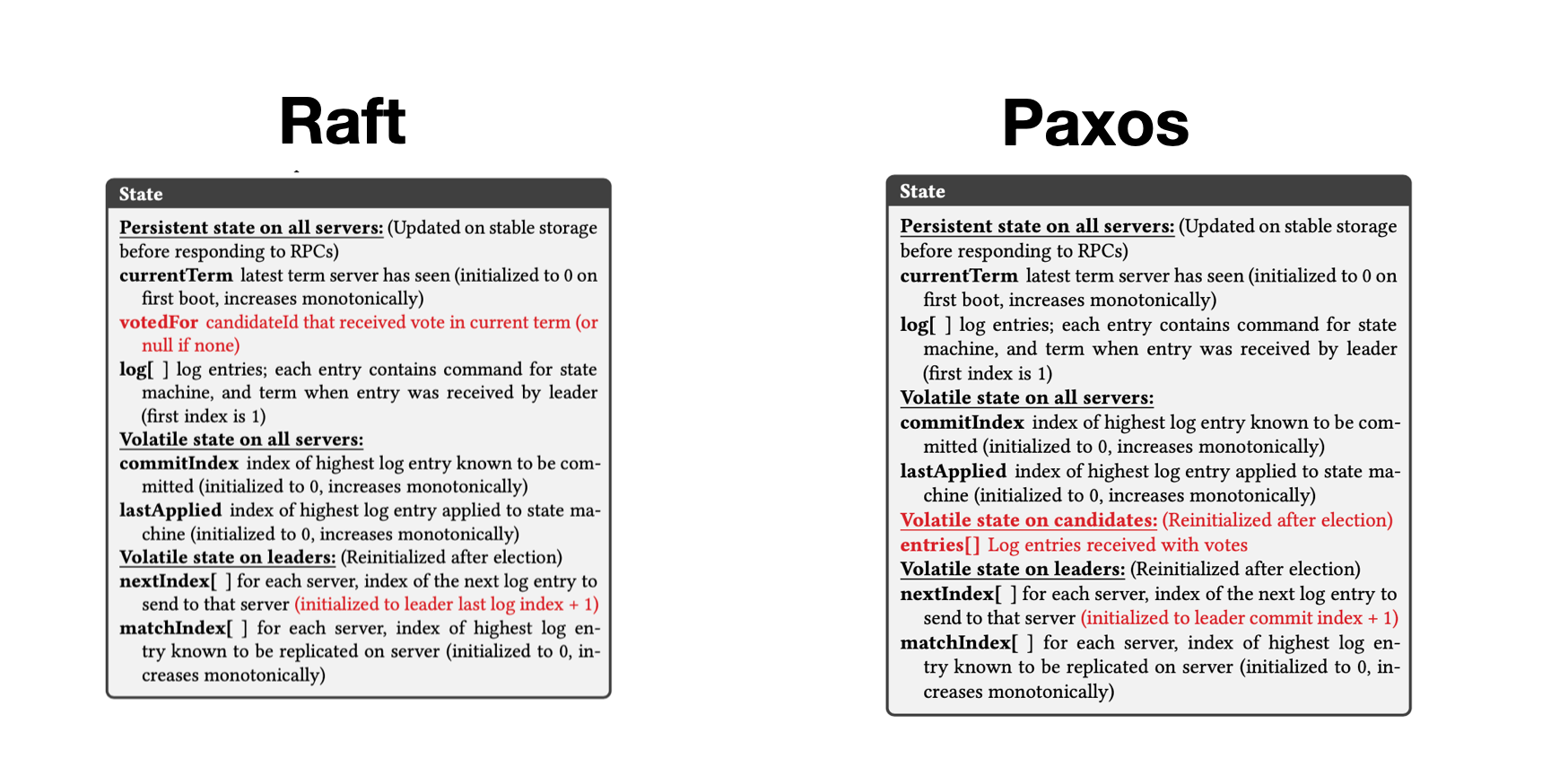
Ở đây, có một số khác biệt cơ bản:
- voteFor: Raft cần thông số này cho điều kiện up-to-date
- state on candidate: Paxos cần giữ một list entry trên từng node, với mục đích merge lại sau khi vote thành công.
Tuy nhiên, khác biệt đáng kể nhất là nextIndex, do được quy định bởi leader election.
Raft: Sau khi một node trở thành leader, node đấy là up-to-date, do vậy mặc định các node khác ít nhất cần phải khớp tới last log index của leader.
- Do vậy ta set nextIndex sẽ là
last log index + 1 - Tuy nhiên, ta cần lưu ý là: có thể follower đã bị quá chậm so với leader. Do vậy, khi ta sync log từ
last log index + 1, ta nhận ra đoạn log này là chưa đủ, và do vậy cần phải lùi lại từ từ đến khi phù hợp (Optimistic approach). Ta có thể tham khảo kĩ hơn ở bài về Raft.
Paxos: Do Paxos không đảm bảo leader có latest log. Nhưng chắc chắn một điểm là log sau khi commit, buộc phải xuất hiện trên mọi node mà có term lớn hơn term của commit log entry đó. TL,DR: khi một log được commit, enventually log entry đấy phải được commit trên mọi node. Do vậy, ta có thể safe assume rằng các node đều sẽ có thể start được từ leader commit index.
- Do vậy, ta set nextIndex là
leader commit index + 1 - Tuy nhiên, ta cần lưu ý là: có thể follower đã bị quá chậm so với leader. Do vậy, khi ta sync log từ
leader commit index + 1, ta nhận ra đoạn log này là chưa đủ, và do vậy cần phải lùi lại từ từ đến khi phù hợp
Rule on leaders

Đây là một khác biệt không tường minh giữa Raft và Paxos.
Trước hết, nói về Paxos, implement rất đơn giản: nếu tồn tại một giá trị N mà quá bán các node nhận được log entry tới index N, ta set commit Index là N.
Tuy nhiên, ở Raft, điều này không đủ. Và nói ngắn gọn, ta không thể commit một log entry ở term trước ở term hiện tại khi chưa có message nào ở term hiện tại được commit. Sau đây là hình minh họa về một scenario replicate log ở Raft:
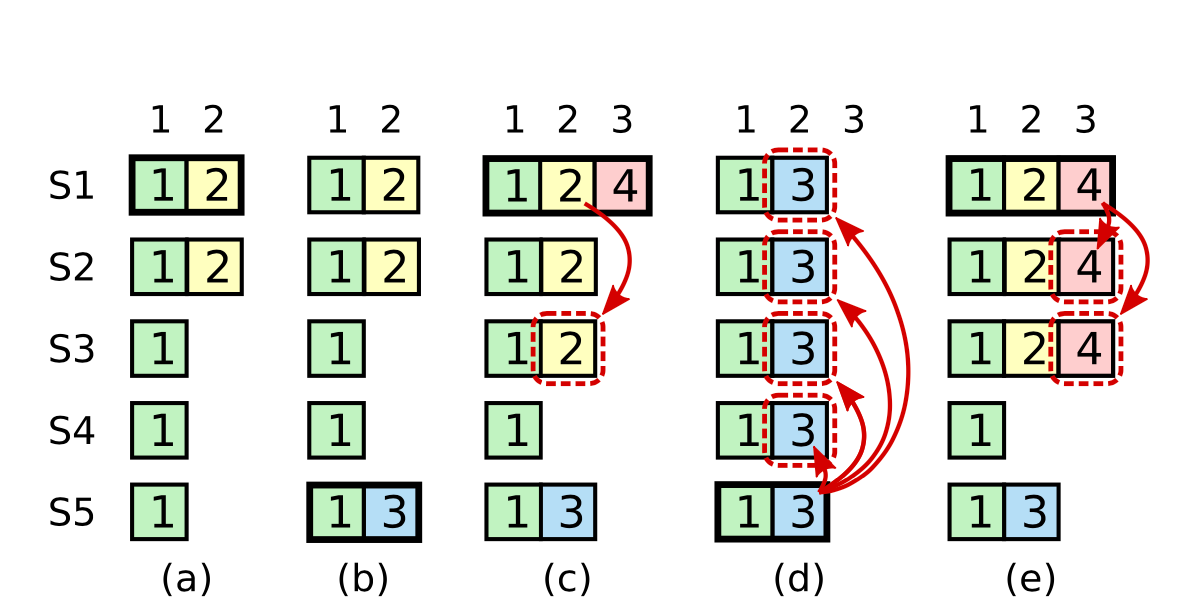
Giải thích hình vẽ:
- Cột a: S1 là leader ở term 1 và 2 và đã replicate một phần log entry ở term 2 (màu vàng)
- Cột b: S1 crash, S5 trở thành leader ở term 3 do nhận được bầu chọn từ S3 S4 và S5 (do vậy vẫn thỏa mãn tính tính chất up-to-date trong leader election - S2 chắc chắn sẽ reject S5 do điều kiện up-to-date). Sau đó, S5 đã accept một log entry ở term 3 tại index 2 như hình vẽ.
- cột c: S5 crash, S1 khởi động lại và được bầu chọn làm leader ở term 4. Theo như phân tích về log replication ở phần trước, log ở term 2 (màu vàng) sẽ được replicate qua các node khác. Sau đó S1 accept thêm một log entry ở term 4 tại index 3 như hình vẽ. Ta lưu ý: tại thời điểm này, log entry ở term 2 đã xuất hiện trên quá bán, nhưng ta vẫn chưa commit. Ta sẽ hiểu rõ hơn tại sao thông qua trường hợp ở cột d.
- cột d: Nếu S1 crash và S5 trở lại làm leader ở term 5 (với vote từ S2; S3 và S4) và ghi đè toàn bộ nội dung log ở các node khác bằng log entry ở term 3. Lưu ý: Ta lại tiếp tục thực hiện quy luật là chưa commit log ở term 3 dù đã xuất hiện quá bán các node (do đang chạy trên term là 5)
- cột e: Minh hoạ một trường hợp S5 không thể trở thành leader. Nếu ở (c), leader S1 khi đó kịp thời replicate log entry ở term 2 và 4 ra quá bán các node, thì S5 không thể dành được đa số phiếu bầu để trở thành leader được (không thoả mãn tính chất log phải up-to-date)
Giải thích: Qua ví dụ trên, ta thấy nếu từ vị trí cột c, ta cho phép log ở term 2 commit (trả về cho client), sau đó log tại vị trí này có thể bị override tại thời điểm tương lai (cột d) → tạo ra trạng thái inconsistent trong hệ thống (xoá đi một log đã được commit). Do vậy, ta sẽ không bao giờ commit trực tiếp một log entry ở term nhỏ hơn term hiện tại bằng phương pháp đếm số node đã replicate trên chính entry đó.
Nhận xét: Trong trường hợp như ở cột (c), nếu sau khi S4 lên làm leader nhưng đồng thời không nhận được bất cứ request nào mới từ client, có thể các entry ở term 2 và term 4 không bao giờ được commit. Đây là lí do mà một số thư viện implement Raft, ví dụ như tikv/raft-rs, leader ngay sau giải đoạn leader election sẽ tạo ra một no-op message nhằm mục đích buộc quá trình commit này diễn ra trên toàn bộ log entry cũ.
So sánh cùng cấu hình, nhưng với thuật toán Paxos:
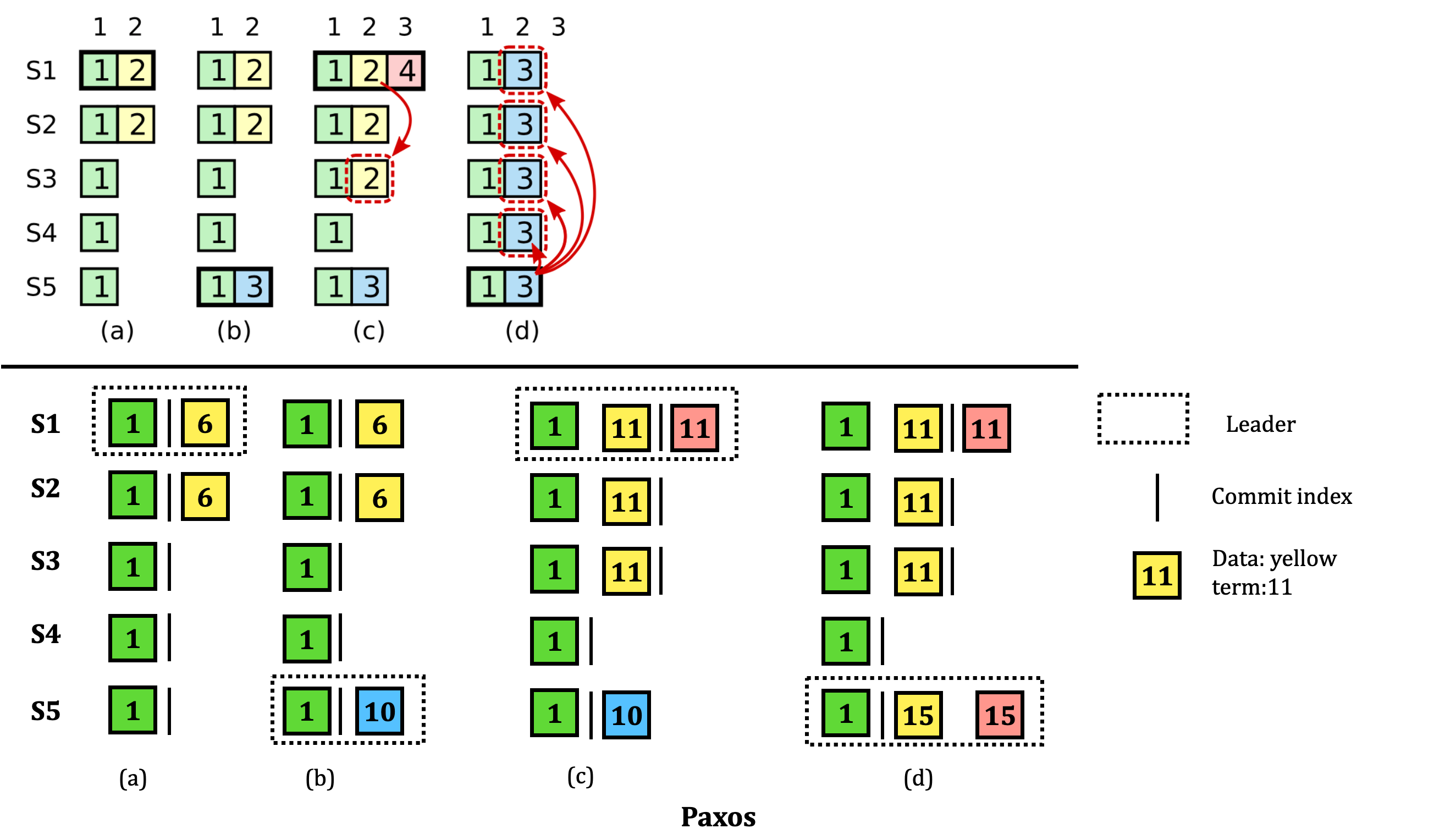
Ta nhận xét:
- (a): S1 là leader với term 6.
- (b): S5 là leader (quorum: 3-4-5), với term 10. Một log entry ở index thứ 2 được tạo ra
- (c): S1 là leader (quorum: 1-2-3), với term 11. Các log entry cũ chưa được commit được replicate với term mới là 11. Commit index lúc này = 2. Một entry mới tại index thứ 3 được tạo ra.
- (d): S5 là leader (quorum: 1-2-3-4-5). S5 learn được mọi log ở các node khác, replicate về local, và đổi thành term hiện tại. Ta thấy log entry “xanh dương” bị replicate bởi log entry vàng vì lí do term bé hơn.
Như vậy ta thấy ở (c), S1 commit khi một log entry được quá bán, dù log entry đấy xuất hiện ở term trước nhưng không có vấn đề giả xảy ra. Lí do:
- Raft: Luôn cố gắng giữ term tại một log entry không thay đổi
- Paxos: Nếu một log entry được replicate ở term trước, Paxos sẽ cập nhật lại log entry ở term hiện tại.
Từ ý nay, ta đặt một câu hỏi: liệu thật sự Raft có dễ hiểu hơn Paxos hay không?
Performance
Leader election ở Raft ban đầu có vẻ thiếu hiệu quả hơn: các candidate sẽ phải cạnh tranh trên cùng một term, và điều này có thể dẫn tới việc leader election diễn ra vô thời hạn. Raft xử lí bài toán này bằng random timeout.
Tuy nhiên, Raft có vẻ lightweight hơn Paxos trong rất nhiều trường hợp.
-
RequestVote: Raft chỉ cho phép candidate có log up-to-date trở thành leader, do vậy Raft không yêu cầu các follower phải send log tới candidate lúc voting. Ở Paxos, ngược lại, cần yêu cầu việc send log từ follower về candidate. Có những bước tối ưu để giảm thiểu số log cần send, nhưng vẫn phải có, trong trường hợp leader vẫn chưa up-to-date.
-
AppendEntries: Raft, khi một node trở thành leader, leader có nhiệm vụ phải synchronize log về lại các follower. Ở Paxos, do log entry có thể bị thay đổi term (e.g.: chưa được commit trên leader → thay đổi thành term hiện tại), do vậy, các log entry cần được synchronize back về follower (dù nội dung không thay đổi)
Tổng kết
Tổng kết lại, hai thuật toán có những khác biệt cơ bản sau:
- Paxos chia term giữa các server. Raft cho phép follower trở thành candidate ở bất cứ term nào, nhưng chỉ có tối đa một leader ở mỗi term.
- Paxos followers sẽ bầu chọn cho bất cứ candidate nào. Raft followers chỉ bầu chọn khi mà log ở candidate phải up-to-date với follower.
- Nếu leader có uncommitted log entry ở term trước, Paxos sẽ replicate qua các follower ở term hiện tại. Raft sẽ replicate ở cùng term của chính log entry đấy.
Từ đấy, nếu ta nhìn lại thuật toán Paxos, dưới lăng kính từ implementation của Raft, ta sẽ thấy hai thuật toán đều có nhiều đặc điểm chung: sử dụng State Machine Replication; single leader; … Những khác biệt cơ bản trên chủ yếu sinh ra từ điều kiện leader election.
- Raft: điều kiện leader rất chặt, buộc các node muốn trở thành leader phải chứa thông tin về log đầy đủ nhất. Do vậy, sau khi trở thành leader, node đấy chỉ cần replicate log ra toàn bộ các node follower trong mạng.
- Multi-decree Paxos: điều kiện để trở thành leader lỏng hơn, không yêu cầu một node muốn trở thành leader phải chứa thông tin đầy đủ nhất về log. Do vậy, sau khi một node trở thành leader, thuật toán phải giải quyết việc đồng bộ log giữa leader và follower, để hệ thống đạt được trạng thái consistency.
Nhận xét về paper
Điểm được
- Trình bày dễ hiểu, đồng nhất các khái niệm giữa Paxos và Raft. Từ đó, ta nhận ra không có sự khác biệt đáng kể giữa hai thuật toán. Đồng thời, cho ta thấy việc leader election ảnh hưởng tới toàn bộ protocol như thế nào.
- Có diagram cho Paxos, trình bày dưới dạng engineering-focus.
Điểm chưa được
- Efficiency: chưa có benchmark cụ thể giữa Raft và Paxos
- Tuy rằng ta thấy sự tương đồng và khác biệt, paper chưa trình bày cách có thể (hoặc có thể được không) cách convert một implementation của Paxos sang Raft. Đây là một major improvement vì từ đó, ta có thể apply các optimisation từ các biến thể Paxos (Fast Paxos / Flexible Paxos) qua Raft. May mắn rằng ta đã có một paper giải quyết bài toán này.
Tính chuyển đổi giữa Raft và Paxos
Paper: On the Parallels between Paxos and Raft, and how to Port Optimizations
TBD