Paper: https://dl.acm.org/doi/pdf/10.1145/2588555.2610507
Kiến thức cần biết
- Database internal: query optimization; database architecture;
- Kiến thức cơ bản về hệ điều hành: memory bus / NUMA / …
Ý tưởng xuyên suốt
- Trên các hệ thống multiple core với kiến trúc NUMA, tối ưu hoá việc query bằng cách lưu trữ và query data trên cùng một CPU node.
- Elastic scheduling: Linh động trong việc phân chia các task để tối ưu hoá toàn bộ resource.
- Cố gắng sử dụng lock-free data structure cho những phần data sử dụng chung.
Các thuật ngữ kĩ thuật
SMP

Problem:
- Số core CPU ngày càng tăng; song song là tốc độ CPU ngày càng vượt trội so với memory
- Tăng memory cache cho CPU (L1/L2/L3) không thể đáp ứng hết hoàn toàn nhu cầu cho các ứng dụng
- Vẫn cần truy xuất main memory liên tục → nghẽn ngay memory bus
NUMA - Non-Uniform Memory Access
hình ảnh CPU AMD Bulldozer sử dụng hwloc tool
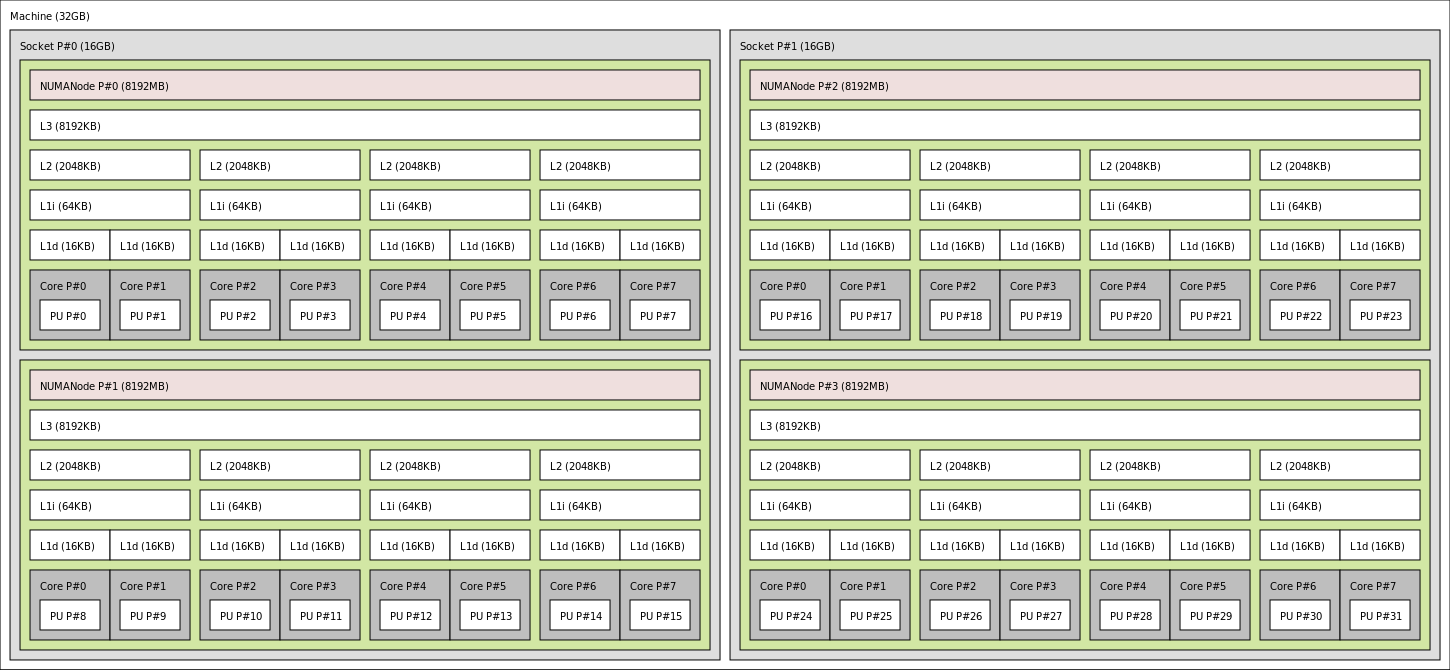
Layout / đường đi giữa các node khác biệt nhau tuỳ vào hãng sản xuất (Intel / AMD) hoặc thế hệ chip (Nehalem / Sandy Bridge)
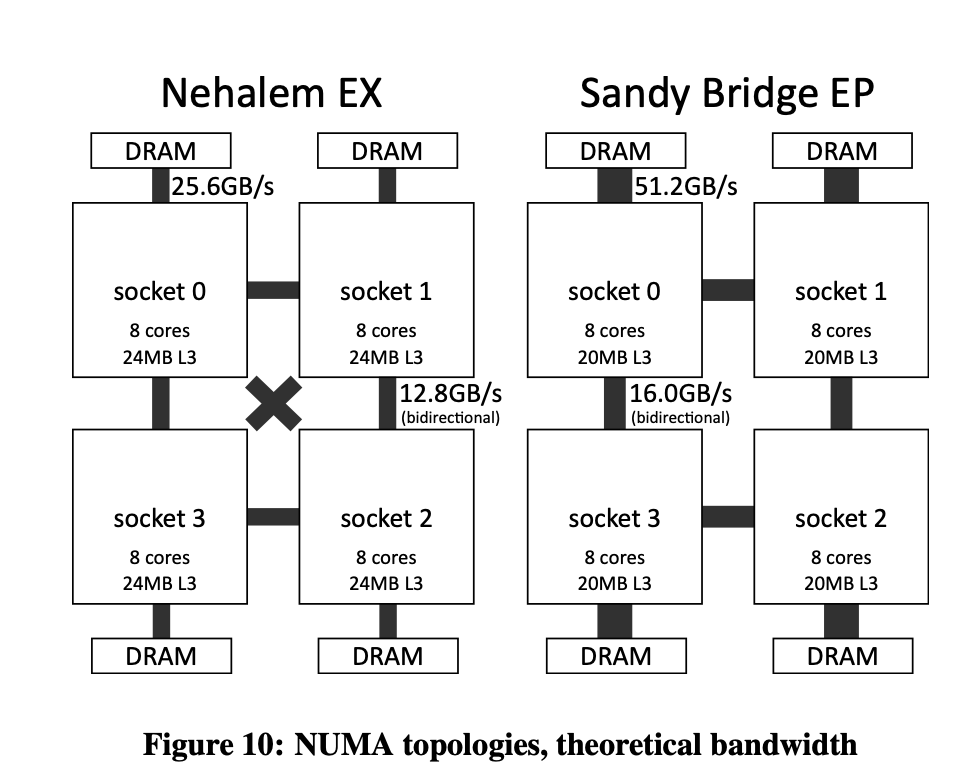
Benchmark từ CoreInfo cho thấy việc giao tiếp cross-NUMA (remote) sẽ có chi phí gấp 1.2 lần so với việc local access.Reference
Naming History
- Intel 2008: QuickPath interconnect
- Intel 2017: UltraPath interconnect
- AMD 2003: Hyper Transport
- AMD 2017: Infinity Fabric
Thống kê về việc nếu ta để data local ở các core sẽ ảnh hưởng performance thế nào
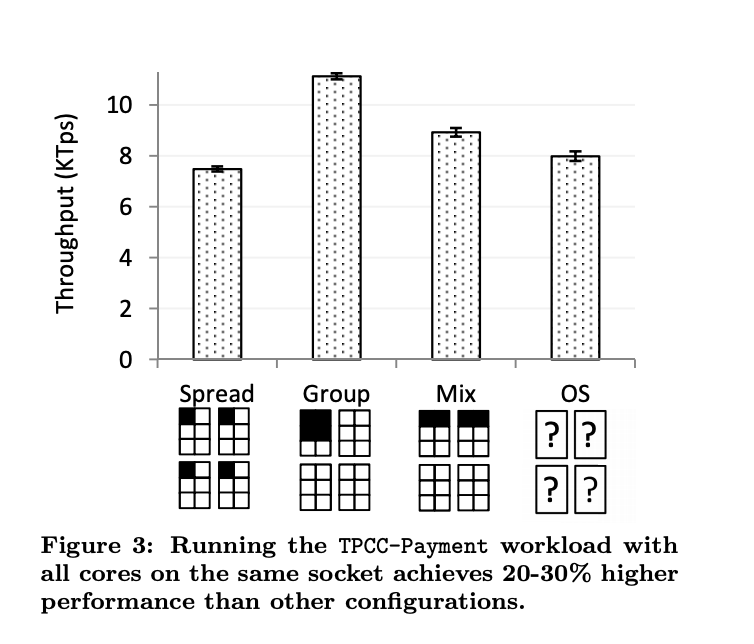
http://vldb.org/pvldb/vol5/p1447_danicaporobic_vldb2012.pdf
Other reference: LWN.net: What every programmer should know about memory, Part 1
Main-memory database
Example: Microsoft SQLServer (Hekaton); MySQL NDB Cluster; Hyper …
Hình ảnh kiến trúc một CSDL có quan hệ thông thường
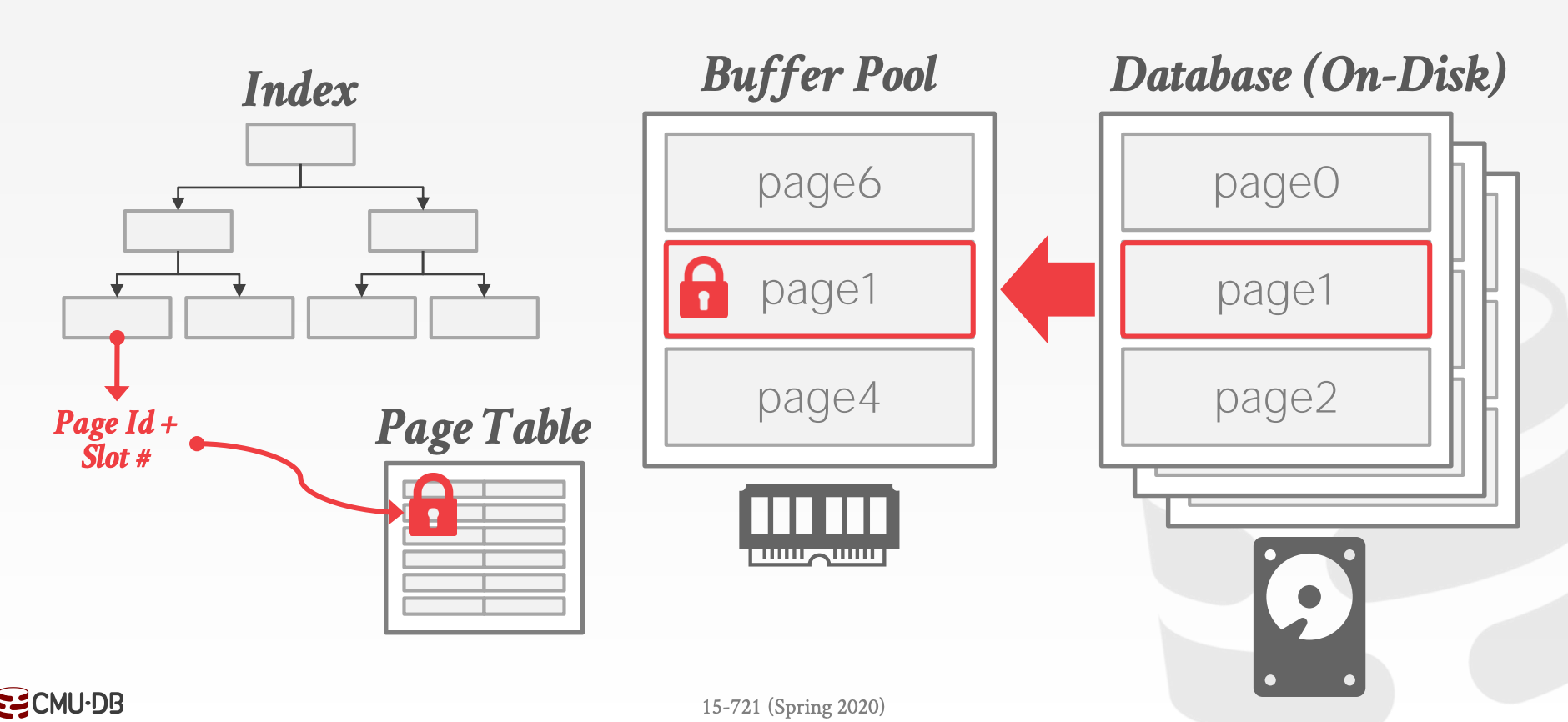
Câu hỏi: với một RDBMS thông thường (Postgres / MySQL / …), nếu tăng kích thước bộ nhớ lên rất lớn thì có thể chạy nhanh bằng một database hoàn toàn run trên memory không
Answer: Không.
- Vẫn có những overhead như kiểm tra record trong buffer pool (dù chắc chắn sẽ trên memory), convert record ID → its’ memory location …
- Chỉ được tối ưu hoá cho việc tối ưu hoá truy xuất đĩa, không phải CPU (vì memory bound)
Thống kê về số memory instructions trong một RDBMS thông thường

http://nms.csail.mit.edu/~stavros/pubs/OLTP_sigmod08.pdf
Query scheduling & optimization
- Quyết định việc một câu lệnh SQL làm sao để thực thi / khi nào / …
- Ví dụ: join 3 bản R x S x T:
- Thứ tự nào sẽ được join để được optimize nhất ? (R x S) x T hay R x (S x T)
- Những column nào sẽ được select để việc lấy dữ liệu là ít nhất
- Hash Join hay Merge Join ?
- Nên dùng thuật toán run song song nào ? Nên chia ra bao nhiêu threads ? Nên store intermediate output ở đâu ?
Hash Join
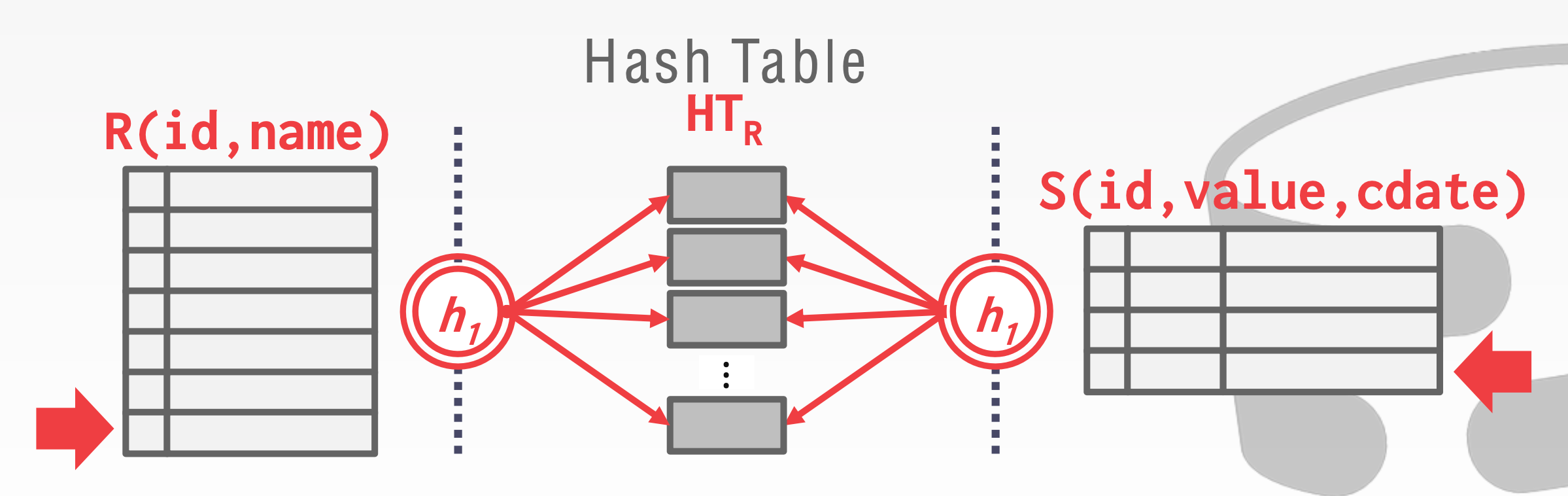
- Hash Join chia thành 2 phase: Build phase + Probe phase
- có thể optimize bằng cách xây dựng thêm một Bloom Filter
Parallel Hash Join
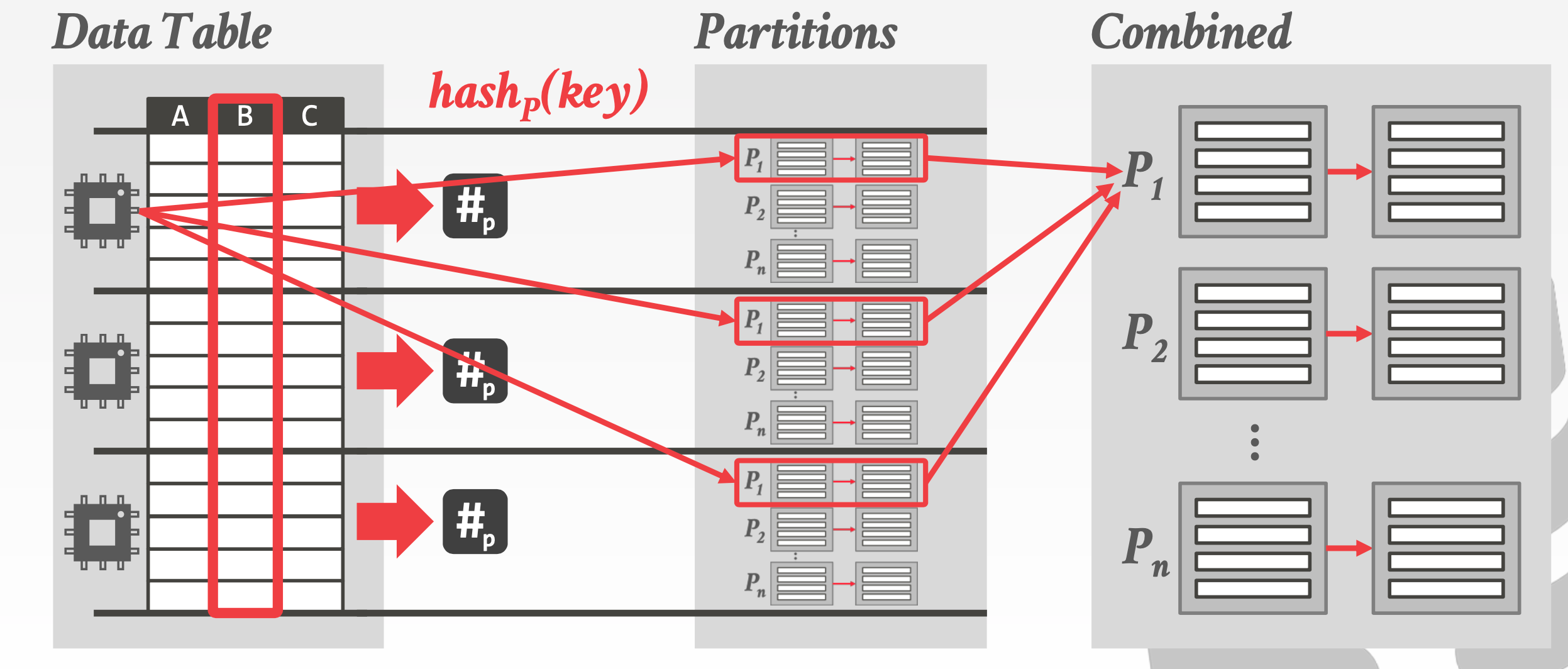
Ví dụ một cách chạy parallel cho thuật toán hash join.
Sort-Merge Join
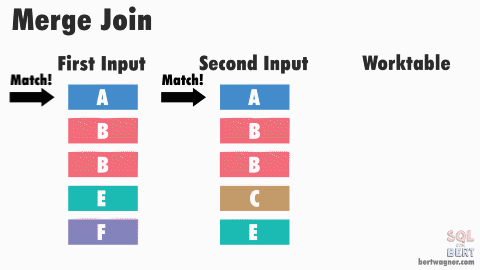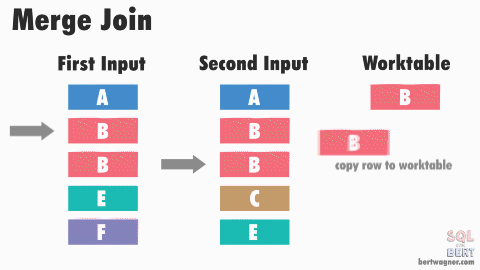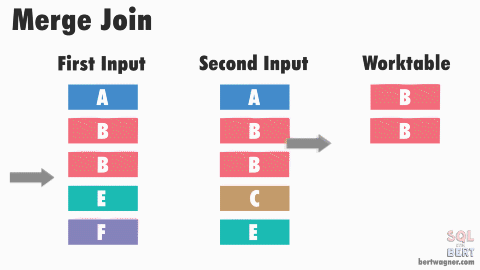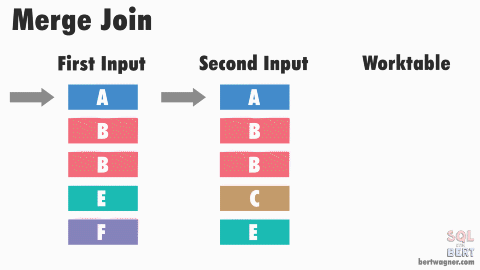
- Data ở mỗi relation sẽ được filter và sort
- Sau đó dùng thuật toán merge để join 2 quan hệ.
Benchmark database
Đánh giá khả năng chạy của các database thông qua các bộ test. Mỗi chuẩn test phụ thuộc vào nhu cầu thực tế của database.
- TPC-E: good for OLTP
- TPC-H: good for OLAP
Tool thường hay sử dụng để benchmark: YCSB
Morsel-Driven Execution
Xét một query giao giữa 3 table: R (with some conditions) x S (with some conditions) x T (with some conditions)
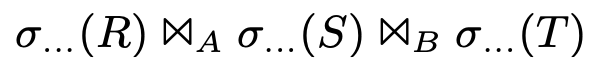
Đây sẽ là bức tranh tổng quát toàn bộ quá trình

Thuật toán tổng quát:
-
Query optimization sẽ quyết định thứ tự join giữa các table (ví dụ: thông qua estimation về size). Như ở đây sẽ là (S x R) x T
-
Như thuật toán hash join ở hình vẽ trên, ở mỗi quan hệ, ta sẽ build một hash table. Ý chính ở đây là ta sẽ tách nhỏ một table thành nhiều phần. Data mỗi phần sẽ được copy qua một vùng memory local với một NUMA node.
-
Khi join các partition giữa 2 relation với nhau, ta sẽ join trên các partition local với NUMA node → hạn chế việc truy xuất dữ liệu ở một node khác.
Chi tiết hơn về việc tạo hash table trên một relation:

- Từng phần (được tô màu) được gọi là morsel.
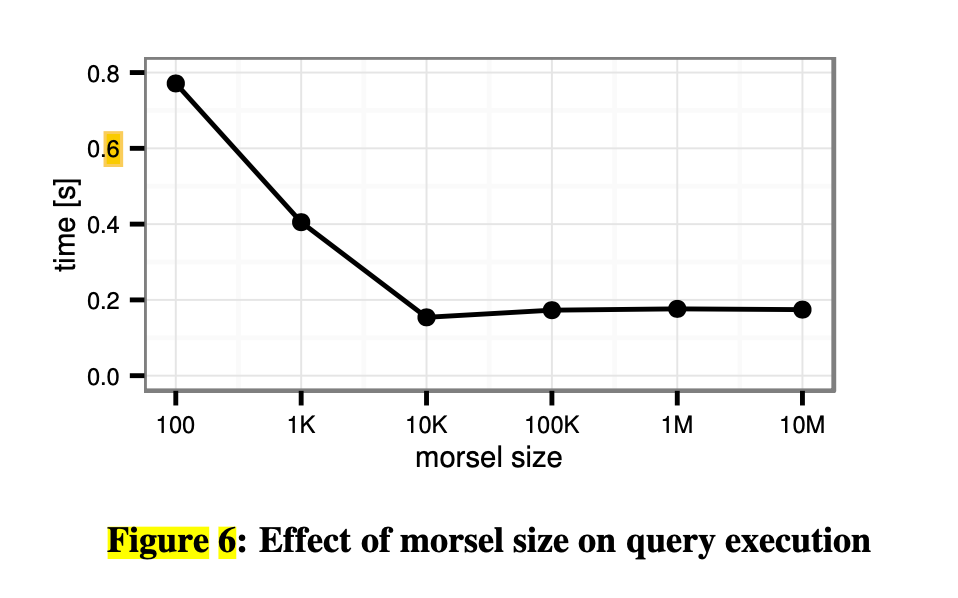
- Morsel có thể hiểu như là một cách partition data: Round-robin hoặc partition theo hash value của một số attributes.
- Phụ thuộc trên từng machine. theo benchmark thì tối ưu là tầm 100k records / morsel
Dispatcher: scheduling parallel tasks
Phần trên là cách thức hoạt động. Tuy nhiên, cần có một controller để quản lí toàn bộ quá trình phân task. Mục tiêu:
- Đảm bảo các morsel được phân chia hợp lí qua các cores để đảm bảo luôn được access local theo NUMA node.
- Phân bổ đều các công việc để đảm bảo các core được kết thúc đồng thời (tối ưu hoá khả năng chạy). Có thể dùng kĩ thuật work stealing
- Dynamic resize số threads
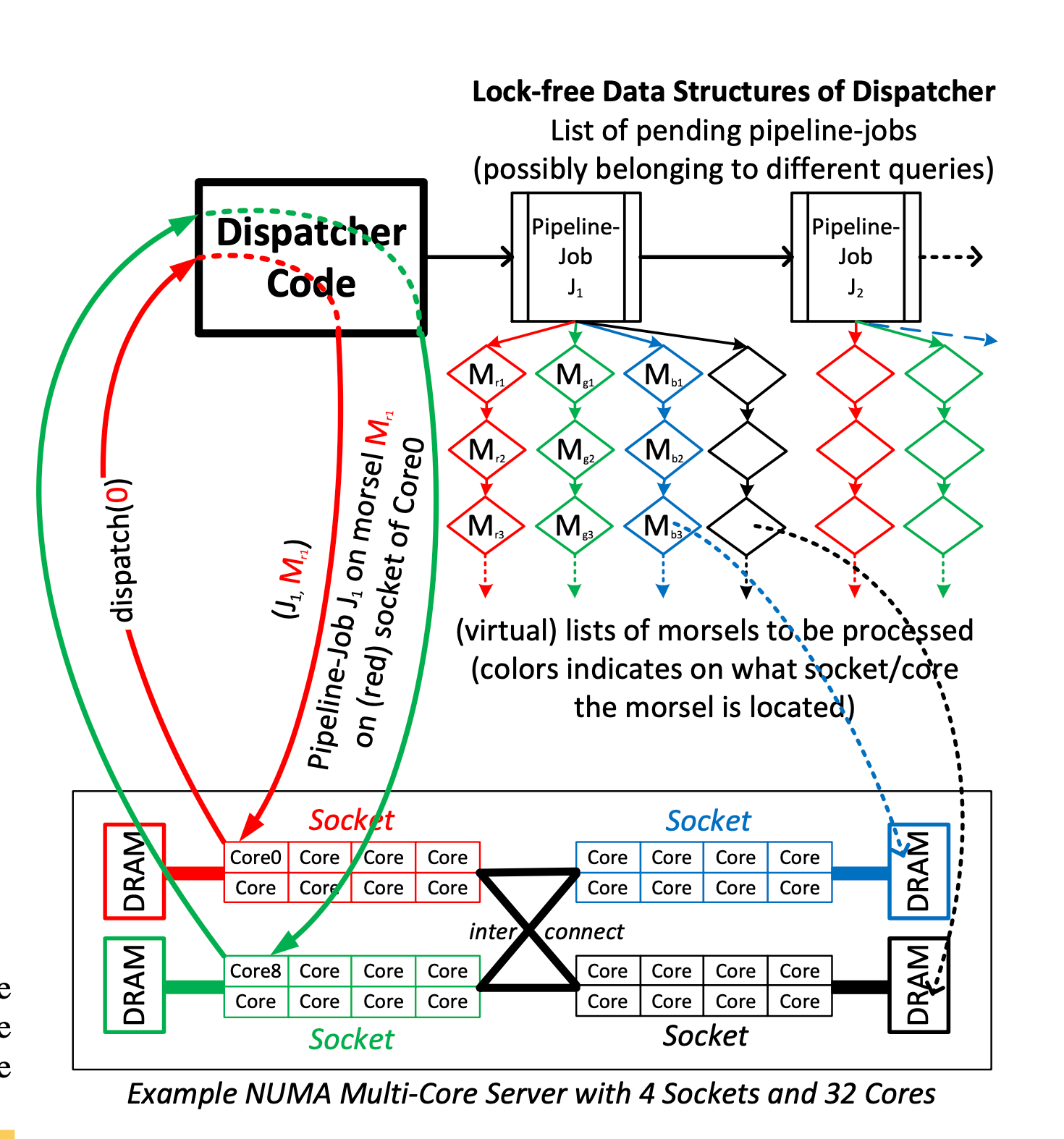
Giải thích
- khi một core request, dispatcher sẽ trả về thông tin metadata về task / morsel core đấy có thể lấy để tiếp tục thực thi.
- Logic của dispatcher có thể được execute trên cùng core của worker’s thread.
- Có một global data structure để lưu trữ thông tin về metadata (những phần nào chưa được assign; nếu assign thì cho core nào ..). được implement bằng lock-free data structure → tránh việc bottleneck khi rất nhiều thread cũng query tại một thời điểm
Nhận xét về paper
Good
- Trình bày được ảnh hưởng của kiến trúc NUMA trong việc optimize quá trình truy xuất dữ liệu
- Có nhiều test trên các kiến trúc khác nhau
- Nhiều kiến thức xung quanh hay. Có nhiều đường dẫn tới những nghiên cứu khác để tham khảo thêm.
Not Good
- Chưa đề cập nhiều về work stealing và ảnh hưởng như thế nào tới thời gian query.
- Chưa đề cập việc nếu dùng hệ thống này trên môi trường distributed system. (thêm các ảnh hưởng từ network thì chắc chắn sẽ ảnh hưởng tới việc query dữ liệu)
- Chưa có so sánh với những main memory database khác có hỗ trợ NUMA (e.g.: Microsoft Hekaton)