Paper https://dl.acm.org/doi/abs/10.1145/2815400.2815425
Kiến thức cần biết
- RDMA - Remote Direct memory access
- NV-RAM: non-volatile RAM
- Basic OS knowledge: network stack.
Tư tưởng xuyên suốt
- Áp dụng triệt để công nghệ RDMA và NV-RAM để tối ưu hóa memory access trong một data center.
- Có thể đạt được cùng lúc consistency và availability trong hệ thống phân tán.
Giải thích thuật ngữ kĩ thuật
Zero Copy
Standard network stack
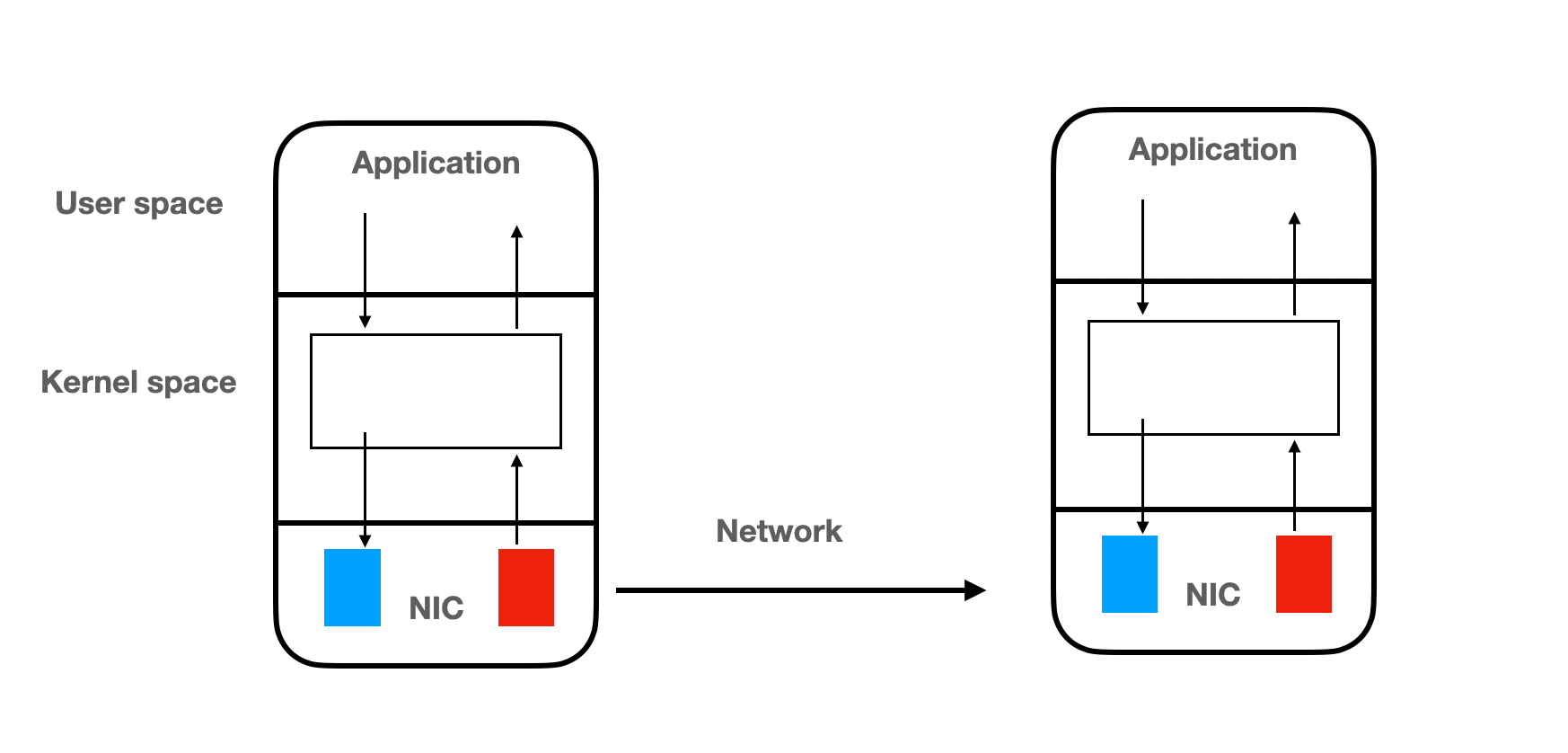
Zero copy

Application: Kafka.
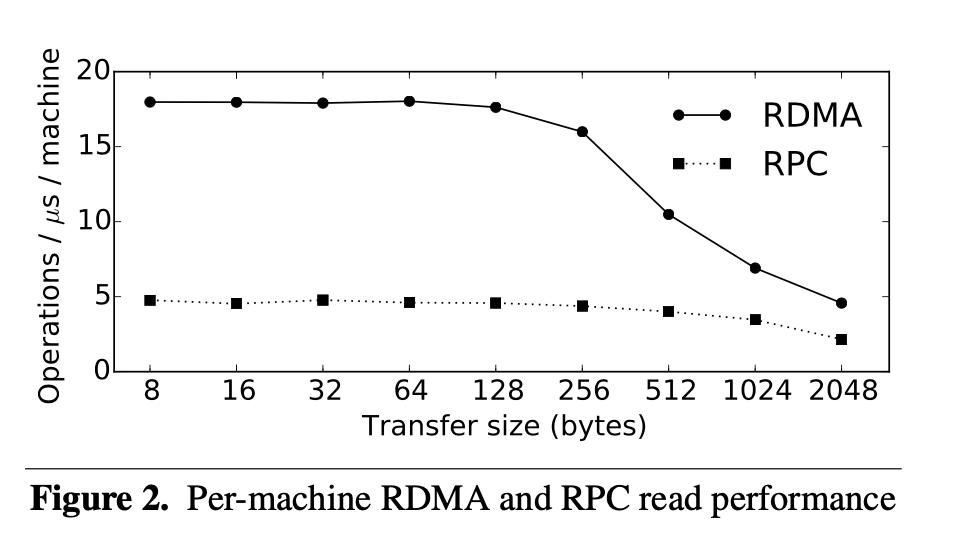
RDMA

Điểm mạnh
- zero copy
- kernel by-pass
- không cần đến remote CPU resource khi đọc remote data
Paper sử dụng RDMA over Converged Ethernet (RoCE)
Non-volatile RAM (NV-RAM)
Là một dạng bộ nhớ như RAM, nhưng không bị mất dữ liệu khi có sự cố về điện.
NV-RAM theo như paper sẽ được implement bằng cách: Khi có sự cố về điện, “distributed uninterruptible power supply” (UPS) sẽ kích hoạt và ghi toàn bộ những data trên RAM vào các ổ SSD. Giải pháp này sẽ rẻ hơn so với dùng non-volatile DIMMs.
- Ưu điểm: Chi phí rẻ hơn so với dùng non-volatile DIMMs.
- Nhược điểm: Hệ thống phải kịp thời backup dữ liệu trước khi bộ UPS hết năng lượng.
Main-memory database
Example: Microsoft SQLServer (Hekaton); MySQL NDB Cluster; Hyper …
Hình ảnh kiến trúc một CSDL có quan hệ thông thường
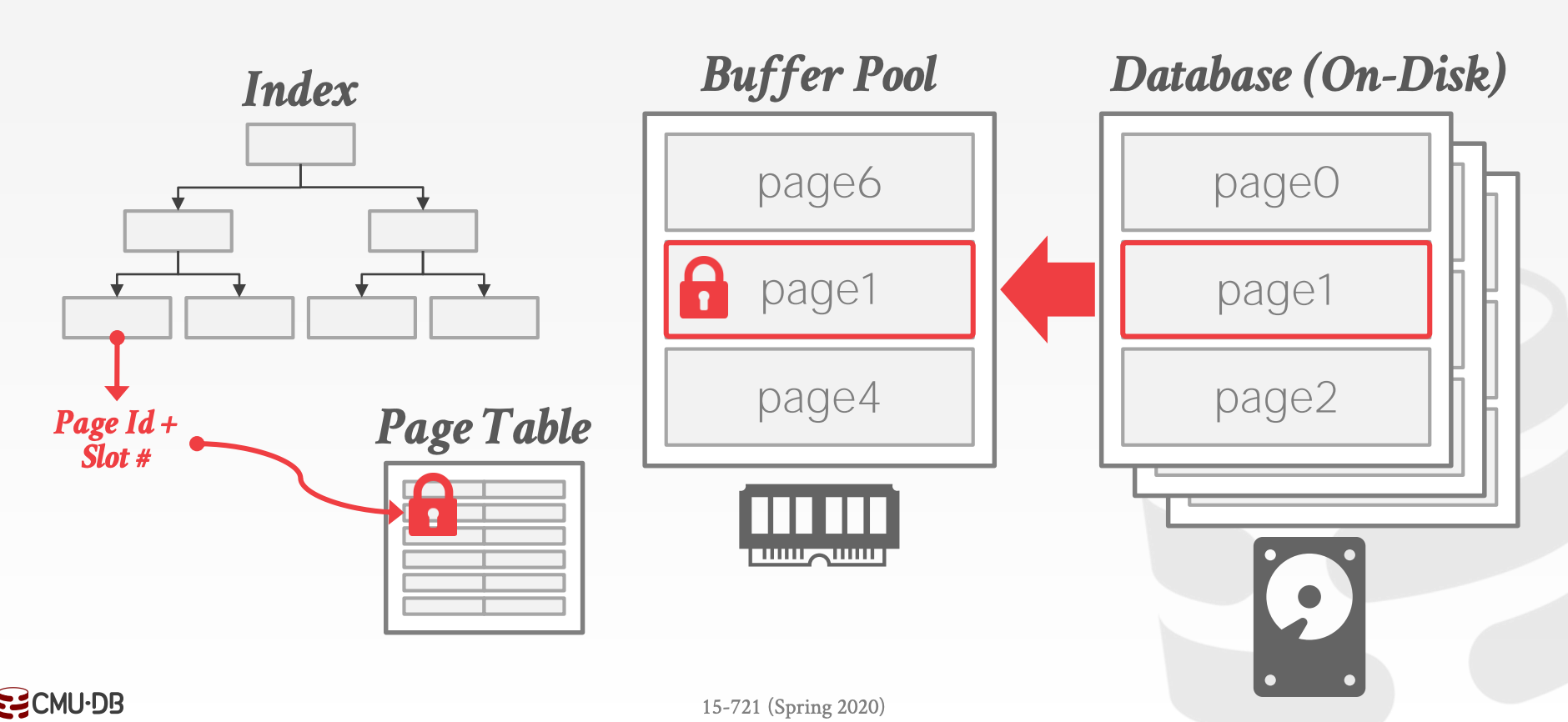
Câu hỏi: với một RDBMS thông thường (Postgres / MySQL / …), nếu tăng kích thước bộ nhớ lên rất lớn thì có thể chạy nhanh bằng một database hoàn toàn run trên memory không
Answer: Không.
- Vẫn có những overhead như kiểm tra record trong buffer pool (dù chắc chắn sẽ trên memory), convert record ID → its’ memory location …
- Chỉ được tối ưu hoá cho việc tối ưu hoá truy xuất đĩa, không phải CPU (vì memory bound)
Thống kê về số memory instructions trong một RDBMS thông thường

http://nms.csail.mit.edu/~stavros/pubs/OLTP_sigmod08.pdf
Isolation & Consistency
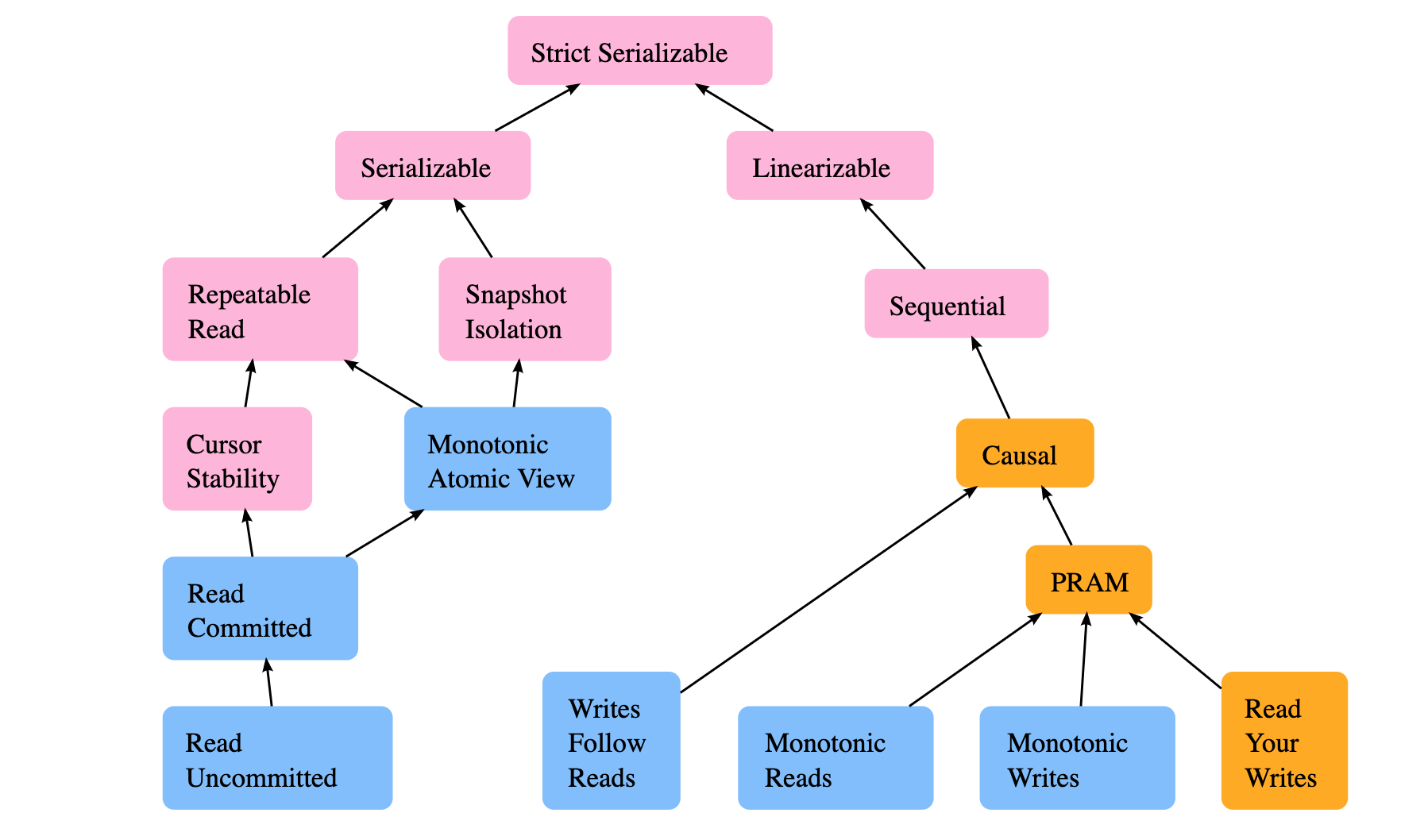
Source: https://jepsen.io/consistency
Giải thích kĩ hơn về Serialization. Giả sử ta có 2 transactions:
Transaction 1
if x == 0
y = 1
Transaction 2
if y == 0
x = 1
Có 3 trường hợp khi thực thi đồng thời 2 transaction trên:
- T1 → T2: x = 0 y = 1
- T2 → T1: x = 1 y = 0
- T1 và T2 run xen kẽ: X = 1 và Y = 1
Thảo luận về paper
Cách xử lí một transaction
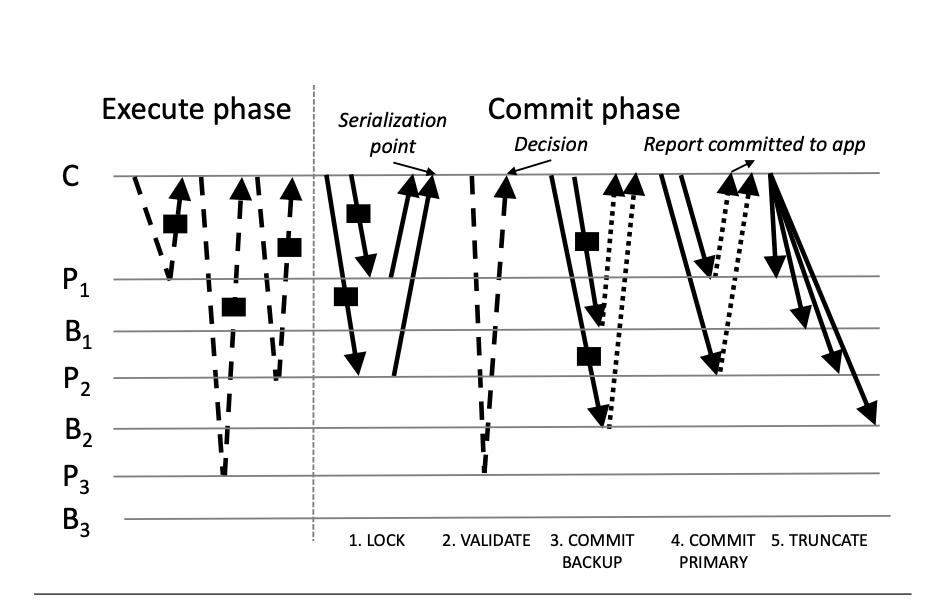
Scenario:
read y
if z == 3 then:
x = 4
y = 5
end
Bước 1: Execution
Coordinator sẽ gửi request đến từng primary partition để get data, và từ đó tiếp tục thực thi trên data đọc được. Giả sử x nằm ở phân vùng P1, y nằm ở phân vùng P2, z nằm ở phân vùng P3.
Bước 2: Lock phase
Coordinator sẽ đến từng primary partition mà có thực thi việc ghi dữ liệu để lock lại record. Việc lock này sẽ làm 2 thứ:
- Kiểm tra xem version của record có thay đổi không
- Nếu không thì sẽ lock record lại. Ngược lại sẽ trả về false. Khi đó, coordinator sẽ dừng lại transaction.
2 thao tác này sẽ atomic thông qua “compare-and-swap”. Theo như ví dụ ở trên, coordinator sẽ gửi request tới P1 và P2.
Bước 3: Validation
Coordinator sẽ đến từng read partition để kiểm tra:
- record có đang bị lock hay không: nếu bị lock return false
- version record có bị thay đổi hay không: nếu có thay đổi return false
- Ngược lại, return true. transaction này có thể thực hiện được.
Câu hỏi: Tại sao lại có thêm bước này ?
Trả lời: đảm bảo strong consistency, tránh một biến bất kì bị thay đổi khi đang thực thi.
Ví dụ một scenario khởi tạo với x = 0 và y = 0
Transaction 1
if x == 0
y = 1
Transaction 2
if y == 0
x = 1
Có 3 scenario xảy ra:
- T1 → T2: kết quả cuối cùng sẽ là y = 1 / x = 0
- T2 → T1: kết quả cuối cùng sẽ là x = 1 và y = 0
- T1 và T2 chạy xen lẫn (cùng vào if condition): y = 1 và x = 1
Ở trường hợp thứ 3 không đảm bảo serializability. Các trường hợp nếu trên đều có thể tránh, nếu từ đầu lock cả record được read. Tuy nhiên, một cách tối ưu hơn là check version của read record (tránh thao tác ghi lock record)
Bước 4: Commit backup
Coordinator sẽ đến từng backup partition của các partition được ghi để commit một bản backup, ở đây là B1 và B2.
Ở đây, việc sử dụng non-volatile là quan trọng, vì dữ liệu vẫn còn tồn tại khi bị power failure.
Câu hỏi mở: nếu ở bước này không sử dụng non-volatile RAM mà sử dụng RAM bình thường và lưu log vào HDD/SDD có được không ?
→ Ý kiến cá nhân: không nghĩ là có thể được, vì việc ghi là từ RDMA card vào RAM. có thể giao thức này không trợ thao tác trên được.
Bước 5: Commit primary
Bước 6: truncate
Failure Recovery / Reconfiguration
TBA
So sánh với Spanner
Ta sẽ so sánh giữa FARM và Spanner qua 3 yếu tố: Deployment; Performance và Consistency.
Deployment
- Spanner: machines can be crossed multiple data centers / different regions
- FARM: all machines are inside one data center (RoCE)
Performance
Spanner
Kết hợp giữa:
- 2-phase commit protocol
- One Paxos group cho một partition.
- One Paxos group cho coordinator (khắc phục nhược điểm của 2-phase commit protocol)
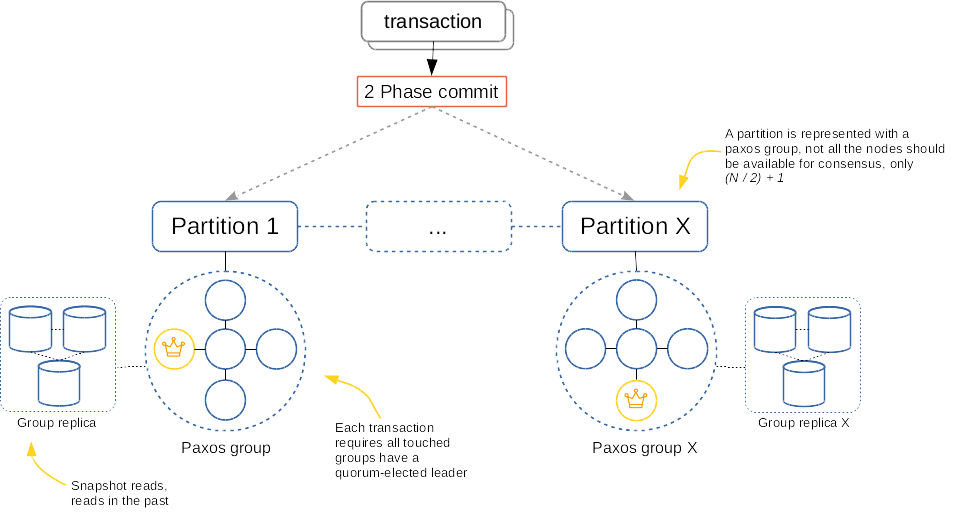
Giải thích
→ cần 2f + 1 node để chịu được f failures (consensus property)
→ Với một node X tham gia vào transaction, số messages cần trao đổi khi đó sẽ là: 2 (i) * 2 (ii) * (2f + 1)
- (i): 2-phase protocol
- (ii): cả coordinator và partition đều nằm trong một paxos group
→ P * 4 * (2f + 1) messages, với P là số partition tham gia vào việc ghi dữ liệu.
FARM
Kết hợp giữa:
- 2-phase commit protocol
- primary-backup replication
- không replicate state cho coordinator
- Giảm đi số messages gửi đi trong hệ thống
- Tuy nhiên, nãy sinh ra một bài toán khác kinh điển khi sử dụng 2PC là: nếu coordinator fail, làm sao để detect và tiếp tục transaction?
- Không cần backup cho read-only partition
→ Chỉ cần f+1 số replication để chịu được f failures
→ Sử dụng P_w * (f + 3) lần ghi cho one-sided RDMA , với P_w là số partition tham gia vào việc ghi dữ liệu.
Consistency
Spanner: External Consistency (using TrueTime API)
FARM: strict serializability
Nhận xét về paper
Tốt
- Cách tiếp cận mới: combine state-of-the-art hardwares để giải quyết bài toán truyền thống về database system (RDMA + NV-RAM)
- Trình bày tốt. Đủ hết các mặt của một database system / distributed system.
Miss
- Sử dụng phương pháp Optimistic locking nhưng chưa đưa ra benchmark khi mà nhiều - transactions conflict sẽ ảnh hưởng xấu tới performance thế nào
- Chưa có benchmark so với các in-memory DB khác.
- MVCC: có thể mở rộng sang MVCC được hay không? Có cần lưu ý gì?
- Chưa được “công bằng” khi so sánh với Spanner: 2 database với 2 requirements khác nhau khi thiết kế.
- Chưa đưa ra so sánh kết quả benchmark cụ thể
- Spanner offer HA cho cross data center hoặc chỉ trong một data center. Sẽ tốt hơn nếu paper so sánh performance giữa FARM và Spanner khi chỉ chạy ở chế độ HA trong một data center.