Bài viết phân tích ưu/nhược điểm của 2-phase commit trong cơ sở dữ liệu phân tán. Từ đó để xuất hướng tiếp cận mới - cơ sở dữ liệu tất định (deterministic database), mục đích tạo ra hệ thống cơ sở dữ liệu phân tán có khả năng scalability trên các hệ thống máy tính thông thường.
Paper
- SLOG: Serializable, Low-latency, Geo-replicated Transactions
- The Case for Determinism in Database Systems
Ý tưởng xuyên suốt
- “deterministic database”: cho phép thực thi một execution plan deterministic, từ đấy hạn chế việc coordination giữa các node - đặc biệt là khi các node khác region. Từ đấy, hệ thống có thể đạt được đồng thời high throughput và strong consistency.
- 2PC is evil, and should be avoided?
Kiến thức cần biết
- Serializability
- Isolation vs Consistency
- Strict Serializability
- Còn được gọi là strong consistency / external consistency
- Google (Spanner) phân biệt khác nhau giữa các loại trên.
- Benchmark database: YCSB / TPC-C
Deterministic Database
Introduction
Nói lại về định nghĩa Serializability: là kết quả các thao tác dưới database, được thực thi theo một trật tự tuyến tính. Tuy nhiên, định nghĩa không quy định trật tự đấy là gì. Do vậy, một CSDL nhận vào 2 transaction lần lượt là T1 và T2, và sau đó thực thi theo thứ tự T2 và T1, là hoàn toàn hợp lệ.
Các yếu tố có thể ảnh hưởng tới order này là gì ?
- thread and process scheduling
- buffer and cache management
- hardware failures
- variable network latency
- deadlock resolution schemes
- …
Các lí do bất định này gây khó khăn một số các thao tác, ví dụ như database replication / horizontal scale database (partition data giữa các node), mà ta sẽ trình bày ở phần sau.
Database Evolution
Single Node Database
Một standard RDBMS sẽ đảm bảo thuộc tính ACID - atomic; consistency; isolation; durability
Sharding / Partition database
sharding / partition database nhằm mục đích horizontal scale database. Để đảm bảo tính “atomic”, cần phải áp dụng thuật toán để coordinate giữa các node trong cùng một transaction, e.g.: 2PC.
Modern database system

Ở kiến trúc database hiện đại, data được partitioning/sharding, và đồng thời đảm bảo fault-tolerance / high availabilty cho dữ liệu. Do vậy, data cần phải được replica ra nhiều node, và hơn nữa, nhiều datacenter, và có thể trải rộng trên nhiều vùng địa lí (regions).
Đồng thời, người dùng cũng kì vọng một database system như vậy có thể đảm bảo được thuộc tính ACID và strong consistency.
2PC và Google Spanner
Như đã trình bày ở phần trước, những lí do bất định gây ra 2 sự khó khăn trong việc thiết kế
Khó khăn 1: Replication
2 server với cùng một initial state, và nhận các transaction request giống nhau có thể có trạng thái database cuối cùng khác nhau.
Một số cách replication:
Post-write replication
write được thực thi bởi một node trước, sau đó replicate qua toàn bộ các node khác sau khi hoàn tất. Ví dụ điển hình là mô hình “master-slave” thường thấy.
Replication with lazy synchronization
Các node replica thực thi transaction độc lập nhau, có thể ban đầu trạng thái database phân kì, những sẽ dần dần hội tụ lại một trạng thái duy nhất. (eventually consistency).
Active replication with synchronized locking
Các node cùng đồng thuận trên một tập write locks
Khó khăn 2: Horizontal scalability
Ở kiến trúc hiện đại, data được partitioned qua nhiều node để đạt được mục đích scalability. Đồng thời, dưới viewpoint của user, hệ thống phải đạt được ACID - hay cách khác, là việc thực thi các transaction như được thực thi trên cùng một node - và tuyến tính. (strict serializability).
Solution: distributed commit protocol, ví dụ: 2PC.
Google Spanner
Publish 2012 (cùng thời gian với CalvinDB), đánh dấu thời gian bắt đầu NewSQL
- hệ thống CP; với high-availability → đảm bảo CAP
- 2PL (2-phase locking) → serializability
- 2PC (2-phase commit) → atomic giữa các shard
- Cùng với consensus (Paxos) + TrueTime API để đảm bảo strict serializabilty.

Các database dựa trên paper này gồm có CockroachDB; YugaBytes; TiDB
2PC Disadvantages
2PC là nội dung trọng tâm trong việc xử lí bài toán strict serializability. Tuy nhiên, 2PC có 2 vấn đề nổi tiếng xảy ra:
- Blocking problem: Khi mà coordinator gặp lỗi, thì toàn bộ transaction sẽ bị block lại và không thể tiếp tục được. Spanner khắc phục bài toán này bằng việc run coordinator dùng consensus để đảm high-availability cho node coordinator.
- cloggage problem: latency lớn do thời gian xử lí ảnh hưởng bởi 2PC protocol và thời gian xử lí conflict (nếu có).
Từ đấy, 2PC trong hệ thống phân tán sẽ ảnh hưởng latency / throughput / scalability / availability
Ngoài ra, để đảm bảo strict serializability, Spanner phụ thuộc rất nhiều vào TrueTime API: miêu tả tính “uncertain” của time, và Google infrastructure có thể đảm bảo delta time < 10ms.
Do vậy, các database xây dựng từ paper Google Spanner, không hể đảm bảo được CAP consistency, ví dụ như CockroachDB -Living Without Atomic Clocks.
Giải pháp
Một giải pháp là sử dụng “deterministic database” (cơ sở dữ liệu tất định). Từ đó, có thể thực thi transaction giữa các replica độc lập mà không cần coordination.
Deterministic databases are able to efficiently run transactions across different replicas without coordination.
Aria: A Fast and Practical Deterministic OLTP Database - Yi Lu; et. al
Kiến trúc
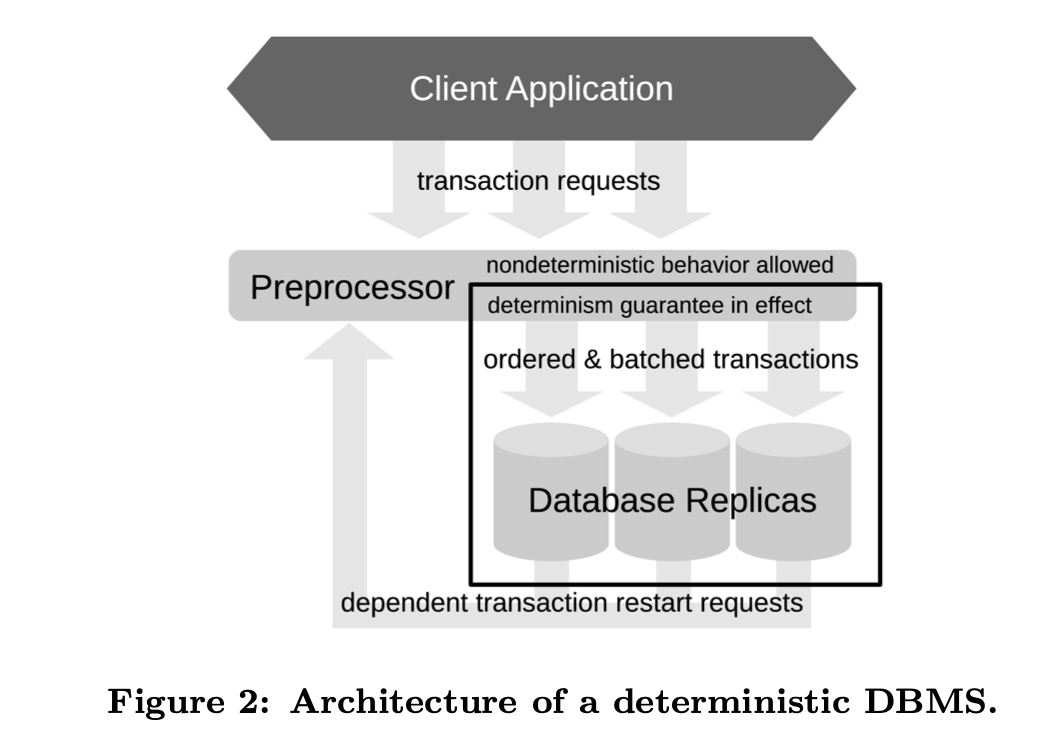

Giải thích
- Sẽ có một preprocessor, để re-write lại các non-deterministic behaviors (random / time.now) thành deterministic behaviors
- Centralize log, để order toàn bộ events
Tại sao việc sử dụng một “deterministic database” có thể giải quyết 2 bài toán trên ?
Khó khăn 1: Replication
Toàn bộ transaction có thể order trước tiên ở một centralize server (ví dụ: ghi vào centralize log), sau đó, gửi đi toàn bộ các transaction này độc lập qua các replica để thực thi. Từ đó, các node có thể đạt được trạng thái consistent mà không cần đến synchronization / pre-agreement / …
Khó khăn 2: Horizontal Scalability
Deterministic database chỉ cần sử dụng “1-phase commit” protocol (ví dụ: SLOG) → các replica có thể thực thi các transaction song song → do vậy, một replica fail không gây ảnh hưởng việc commit/abort một transaction ở replica khác.
Hướng đi này dựa trên một nhận xét: Trong một transaction, events khiến một node không thể commit local chia thành 2 nhóm:
- deterministic events: transaction logic buộc phải abort.
- non-deterministic events: ví dụ như node failure; network failure; …
Trong mô hình 2PC, một giả định quan trọng được đưa ra: một transaction có thể bị abort tại bất cứ thời điểm nào, cho bất cứ lí do gì. (hay cách khác, toàn bộ các events nêu trên)
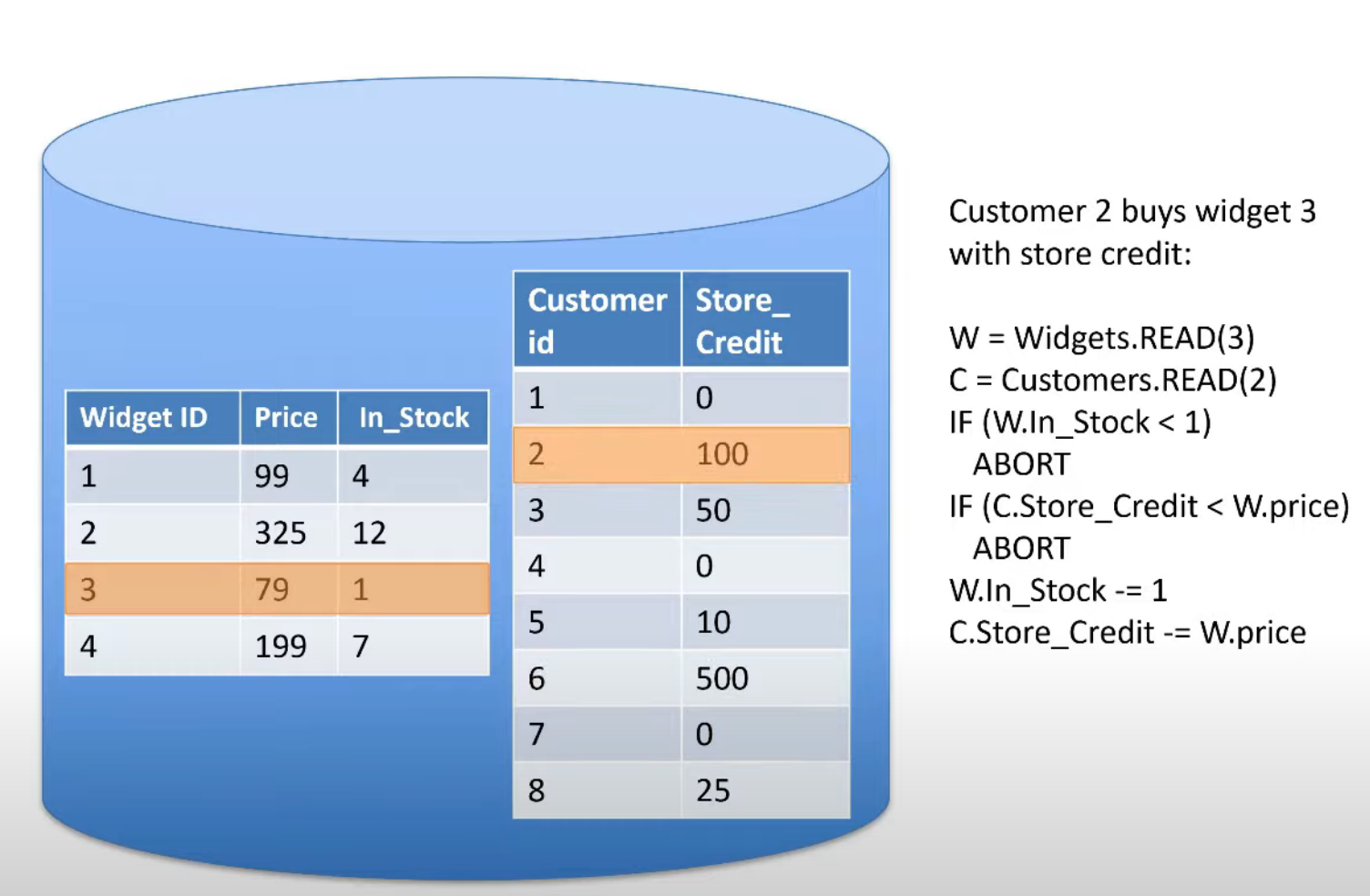
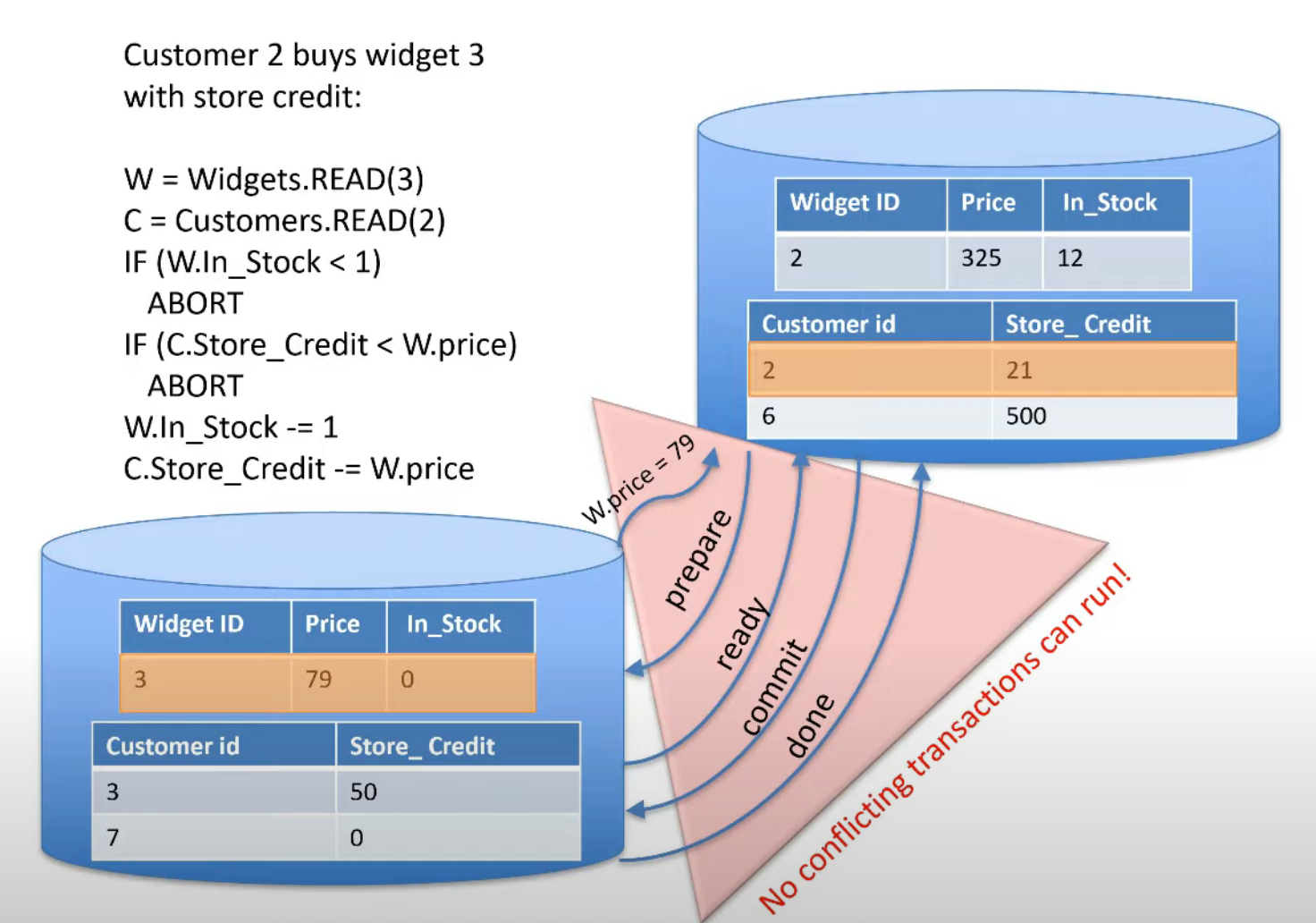
Ví dụ: coordinator X arrange transaction giữa 2 node master A và B; vì lí do network connection giữa coordinator X và node master B (undeterministic error), transaction không thể thành công được. Giả sử hệ thống được replicate ra ở 2 region (như hình vẽ trên), thì buộc coordinator X phải chờ cho transaction được replicate thành công ở toàn bộ các replicas.
Nếu ta chỉ cho phép một transaction abort, lí do bởi nội tại một transaction, hay cách khác, một deterministic event, ví dụ:
x = getA();
if x < 0:
abort
y = x + 3;
Thì ta có thể chuyển về một “deterministic execution plan”, và từ đó các replica giữa các region có thể hoạt động song song được.
Tuy vậy, trong trường hợp này, làm sao để đảm bảo tính consistency cho hệ thống, vì có thể 2 replica chứa 2 trạng thái khác nhau tại cùng một thời điểm? Ta có thể quy định rằng, mỗi data chỉ có một master quản lí. Mọi request write và linearizable read, đều phải đi qua replica này.
Điểm yếu của deterministic database
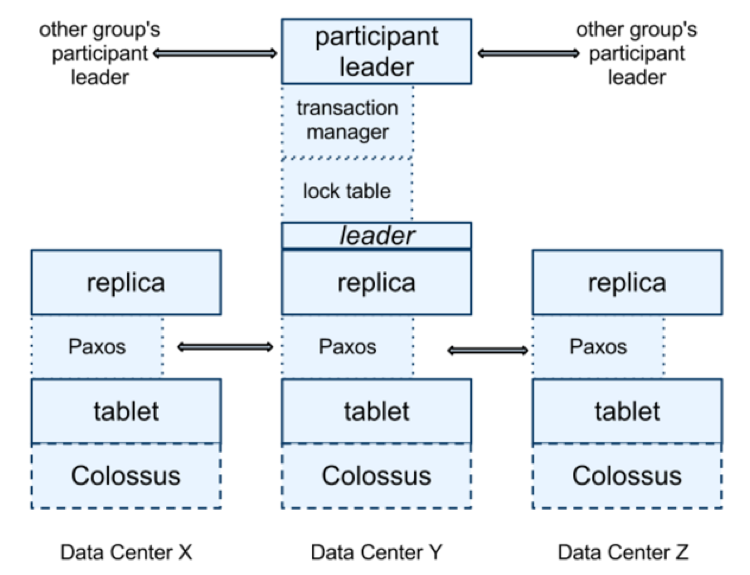
1. Centralize Log
Khác với mô hình như Spanner, client có thể chọn bất kì một participant leader để làm coordinator, đồng thời kết hợp 2PC và TrueTime API để đạt được strict serializability, mô hình deterministic database cần một centralize log để ordering.
Centralize log có thể implement bằng consensus, để đảm bảo được ordering và fault-tolerance, nhưng tạo ra điểm yếu là tăng latency. Do vậy, mô hình này không phù hợp cho hệ thống cần low latency, ngược lại, thích hợp cho hệ thống cần high-throughput.
Tuy nhiên, theo benchmark, một hệ thống consensus có thể scale up to 500,000 tx/seconds.
2. Predetermined knowledge of transactions
Mô hình này cần phân bố transaction ra các node để thực thi độc lập, do vậy việc biết trước toàn bộ các node sẽ tham gia vào transaction là cần thiết.
Do vậy, ORM, hoặc các ứng dụng send một transaction từng bước nhỏ, sẽ không phù hợp. Phần cuối báo cáo giới thiệu một paper có thể khắc phục nhược điểm này.
SLOG Database
Giới thiệu
Theo như paper, là database đầu tiên đồng thời thỏa mãn 3 yếu tố:
- strict serializability
- low latency write (cho một số transaction)
- high throughput, bất kể dưới môi trường high conflict / multi-region transaction
Thuật toán
Thuật ngữ
Local log:
- mỗi region sẽ maintain một local log: chỉ chứa các log entry mà sẽ được thay đổi tại node master thuộc region đấy. Được replicate bằng Paxos.
- để tăng hiệu năng, các input này sẽ được synchronize qua các region khác theo batch
Global log:
- mỗi region sẽ maintain một global log: chứa tất cả các transaction - local log và remote log; single-home và multi-home.
- global log trên các region có thể có các thứ tự khác nhau, nhưng thứ tự tương đổi của một region K bất kì trên một region N vẫn được giữ nguyên (partial ordering).
Single-home transaction: Transaction mà toàn bộ các master server quản lí các key, đều nằm trên cùng một region.
Multi-home transaction: Transaction mà master server quản lí các key, phân bố trên nhiều region.
![]()
Luồng thực thi
- Bước 1: Client gửi request tới một node bất kì trong hệ thống
- Bước 2: Node nhận được request, sẽ chạy thuật toán, dựa trên data, tìm tất cả các node master sẽ sử dụng trong transaction.
- Bước 3: Nếu tất cả các node master cùng region → Single-home transaction, ngược lại, Multi-home transaction.
Single-home transaction
![]()
Multi-home transaction
![]()
Benchmark
So sánh giữa 3 database system:
- Spanner: sử dụng 2PC protocol
- SLOG-B: only replicate data trong cùng một data center
- SLOG-HA: replicate data ra các nearby region.
- Calvin: cũng theo kiến trúc deterministic database, và được sử dụng để implement SLOG.
Khác biệt giữa Calvin và SLOG
- Calvin: toàn bộ transaction, đều phải được đánh số (sequence) bằng Paxos
- SLOG: phân biệt giữa multi-home và single-home transaction
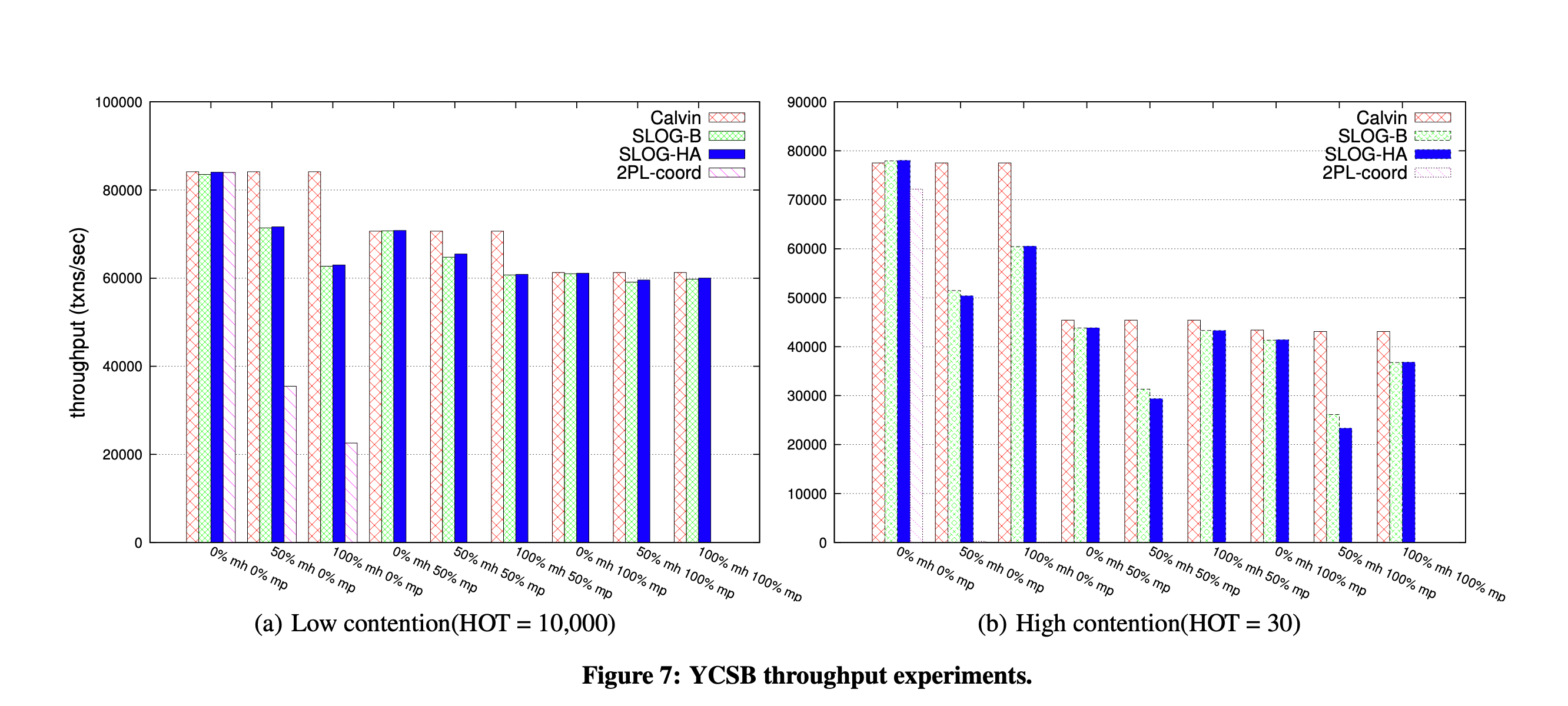
benchmark trên các tiêu chí:
- %mh - %multi-home: % multi-home transaction trên tổng số transaction
- %mp - % multi-partition: transaction mà data nằm trên nhiều partitions (trên cùng một region)
- low/hot contention: đụng độ giữa các transaction
Nhận xét: Với 0% mh, các database sẽ có throughput giống nhau. Tuy nhiên, sẽ bắt đầu khác khi một transsaction span trên nhiều region.
Spanner:
khi transaction bắt đầu span trên nhiều region, performance sẽ bị downgrade rất nhanh. Lí do vì sử dụng 2PC - và phải đợt kết quả từ các region khác.
Lưu ý: Spanner cũng biết được nhược điểm này, do vậy không thực sự cho phép global deployment, mà chỉ cho phép các data nằm trong bán kính 1000 miles. Nguồn
SLOG: Downgrade performance khi %mh tăng và contention tăng lên.
- phải analyze transaction để generate
LockOnlyTxncho mỗi region - conflict transaction. thấy rõ ở 7B
Tuy nhiên, vẫn “competitive” khi so với Calvin, và không downgrade performance kinh khủng như Spanner. Lí do:
- 2PC: lock được acquire cho toàn bộ quá trình 2PC: acquire lock; execute tx; waiting; và commit.
- conflict transaction chỉ cần phải chờ từ đầu LockOnlyTxn đến cuối `LockOnlyTxn của cùng một transaction → ảnh hưởng nặng hơn khi contention tăng lên.
Calvin: là database system sẽ handle tốt nhất trong trường hợp multi-region.

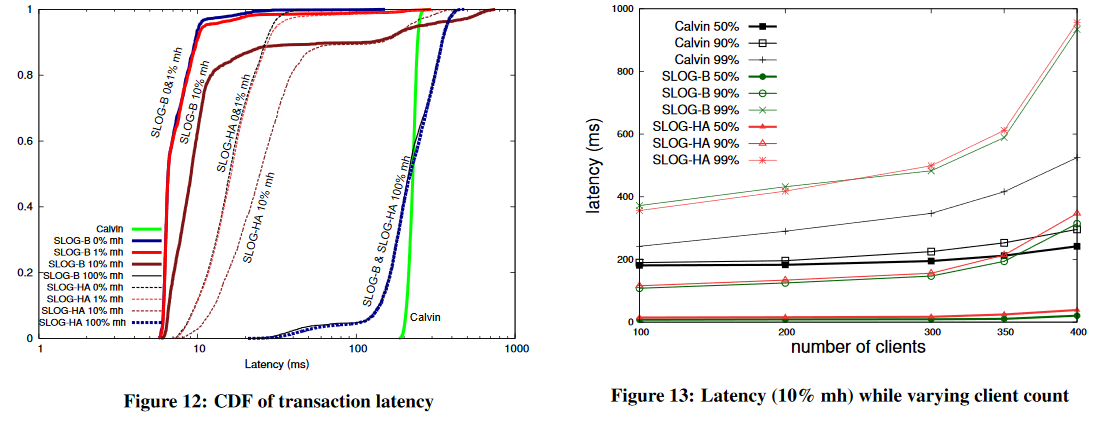
Further Research
Spanner: Google’s Globally-Distributed Database Link
Là paper đầu tiên, ảnh hưởng sâu rộng tới các thế hệ NewSQL sau này, kết hợp 2PC và consensus để đảm bảo strict serializability.
Calvin: Fast Distributed Transactions for Partitioned Database Systems Link
Paper ra cùng thời điểm với paper Google Spanner, nhưng đi theo hướng sử dụng deterministic database.
Aria: A Fast and Practical Deterministic OLTP Database Link
Các deterministic database hiện tại khi thực thi một transaction cần biết trước tập hợp các record đọc/ghi trước khi thực thi (hoặc cần phải restart lại transaction). Paper này giới thiệu phương pháp mà thể thực thi một deterministic query mà không cần analyize trước.

References:
- Introducing SLOG: Cheating the low-latency vs. strict serializability tradeoff
- It’s Time to Move on from Two Phase Commit
- SLOG: serializable, low-latency, geo-replicated transactions
- CMU: SLOG: Serializable, Low-latency, Geo-replicated Transactions
- http://www.cs.umd.edu/~abadi/papers/abadi-cacm2018.pdf
- https://zhuanlan.zhihu.com/p/128994096