Paper: https://arxiv.org/pdf/1707.00788.pdf
Ý tưởng xuyên suốt
Qua bài trước, ta đã tìm hiểu về giao thức SWIM. Tóm tắt lại:
- Membership protocol. Tách ra thành 2 phase rõ ràng:
- Failure Detector: phát hiện node bị lỗi
- Dissemination: lan truyền thông tin node bị fail tới các node khác đang còn hoạt động trong mạng.
- Có những cách optimize để giảm thiểu message load trong hệ thống và giảm thiếu false positive của failure detector (detect fail nhưng thực tế không phải):
- Suspiction mechanism: đưa thêm một trạng thái là suspect. Thay vì nếu không liên lạc được một node X và đưa nó vào trạng thái fail, ta tạm đưa nó vào trạng thái suspect.
- Round-robin probe target: thay vì ở mỗi node, ta sẽ random chọn một node và ping, thì có một xác suất (dù rất nhỏ) một node có thể không bao giờ được ping tới (hoặc rất lâu để được ping tới). Ta khắc phục bằng cách random ra một danh sách và round-robin trên danh sách đó.
- Infection-Style Dissemination Component: Protocol cũ có 3 loại message: ping / ping-req / ack. Tuy nhiên, ta có thể tận dụng 3 message này để “nhồi nhét” thêm các thông tin khác như một node leave / join khỏi hệ thống
Tuy vậy, việc xảy ra false positive cho failure detector vẫn xảy ra. Trong nhiều hệ thống, việc xảy ra vậy gây ảnh hưởng performance nghiêm trọng tới hệ thống.
Paper này tìm cách khắc phục nhược điểm đó, chủ yếu thông qua việc sử dụng dynamic timeout dựa vào “tình trạng của một node” thay vì gán cố định một giá trị xuyên suốt quá trình chạy.
P/S: Tư tưởng này cảm thấy giống như trong giao thức TCP - TCP congression control
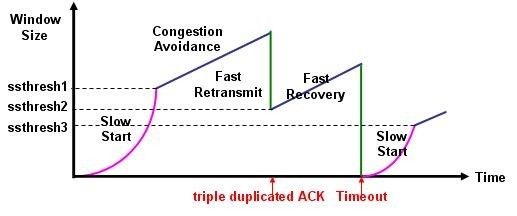
Improvements
Thông qua 3 cách:
- Local Health Aware Probe
- Local Health Aware suspicion
- Buddy System
Improvement 1: Local Health Aware Probe (LHA-Probe)
Self-awareness property:
- Giúp cho một node biết được tình trạng hiện hành của chính node đấy.
- Mục đích: khi một node đang trong tình trạng xấu (e.g.: CPU exhausted), node đấy có xu hướng sẽ report sai thông tin về các node khác. Do vậy, nếu node đấy biết được bản thân đang trong trạng thái xấu, nó sẽ hạn chế việc gửi “lung tung” quá nhiều message tới toàn hệ thống.
Old protocol (SWIM): Định kì kiểm tra node khác với thời gian cố định.
Improvement: linh động thay đổi time tùy thuộc vào việc tình trạng của chính node đấy. Một số nguồn có thể tham khảo:
- Số message ack nhận được so với số message ping và ping-req đã gửi đi. Nếu nhận được response nhiều → chứng tỏ hiện tại bản thân đang ở trong tình trạng tốt. (CPU; network; memory; …)
- Bác bỏ lại gói tin suspect bản thân: chứng tỏ bản thân đang có “vấn đề” nào đó khiến cho một node khác nghi ngờ.
- Thêm “nack” message (not-ack) vào protocol: được send trong trường hợp fail của indirect-ping request. Bằng cách này, node send ping request có thể kiểm tra được response time từ các node được gửi indirect ping.
Đặt ra một biến đếm counter là Local Health Multiplier (LHC)
- successfully probe (ping hoặc ping-req): -1
- failed: +1
- Bác bỏ suspect message: +1
- Probe with missed nack: +1
ProbeInterval = BaseProbeInterval * (LHM(S) + 1)
ProbeTimeout = BaseProbeTimeout * (LHM(S) + 1)
Default implementation value:
- BaseProbeInterval: 1s
- BaseProbeTimeout: 500ms
- S: default with 8
→ Giải thích: ProbeInterval starts with 9s and ProbeTimeout starts with 4.5s.
- One success: giảm thời gian liên lạc với hệ thống thành 8s / 4s
- One fail: tăng thời gian liên lạc với hệ thống lên 10s / 5s
- Min (trong tình trạng rất tốt): 1s / 500ms
Improvement 2: Local Health Aware suspicion
Improvement cho suspicion protocol (improvement of improvement !!!)
Dogpile property
- Các node trong hệ thống sẽ cùng nhau quy định một node đang ở trạng thái suspect bị fail hay không
- Tuy nhiên, khi một node đang có “vấn đề” (network; CPU;…), node đấy dễ dàng đưa node khác vào diện tình nghi hơn. Mặt khác, node đấy khi đó sẽ khó có khả năng nhận được các gói tin suspect từ các node khác. Do vậy, ta có thể optimize bằng cách linh động điều chỉnh thông số suspicion timeout: nếu một node đang ở trạng thái xấu, suspicion timeout sẽ cao hơn, do vậy ảnh hưởng tới toàn hệ thống sẽ nhỏ hơn.
Old protocol: khi một node đưa vào state suspect; node đấy sau một thời gian timeout cố định không có reply sẽ đổi qua trạng thái fail.
Improvement: Thay vào đó, adjust timeout tùy vào tình hình thực tế.
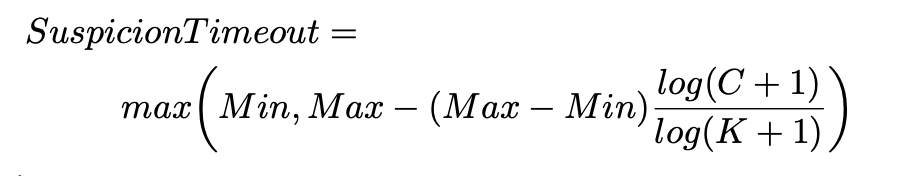
- min / max: min and max of suspicion timeout.
- K: số suspicion nhận được trước khi đưa tham số suspicion timeout về min. Default K = 3
- C: số suspicion member nhận được từ khi suspicion message được raise
Improvement 3: Buddy System
Ở giao thức SWIM, node bị suspect chỉ có thể biết nó bị suspect khi nhận được gói tin suspect từ node khác gởi cho chính nó qua giao thức Gossip. Tuy nhiên, việc broadcast này dẫn đến node bị suspect có thể chờ rất lâu đến nhận được thông tin nó bị suspect.
Do vậy, một node khi nhận được gói tin suspect, sẽ ưu tiên ping tới node đó kèm thông tin node đấy bị suspect. Điều này dẫn đến:
- việc một node bị đưa vào diện tình nghi nhưng thực tế không phải sẽ sớm detect và gửi lại gói tin reject lên toàn hệ thống.
- Improve performance cho cả 2 thuật toán LHA-Probe và LHA-Suspicion
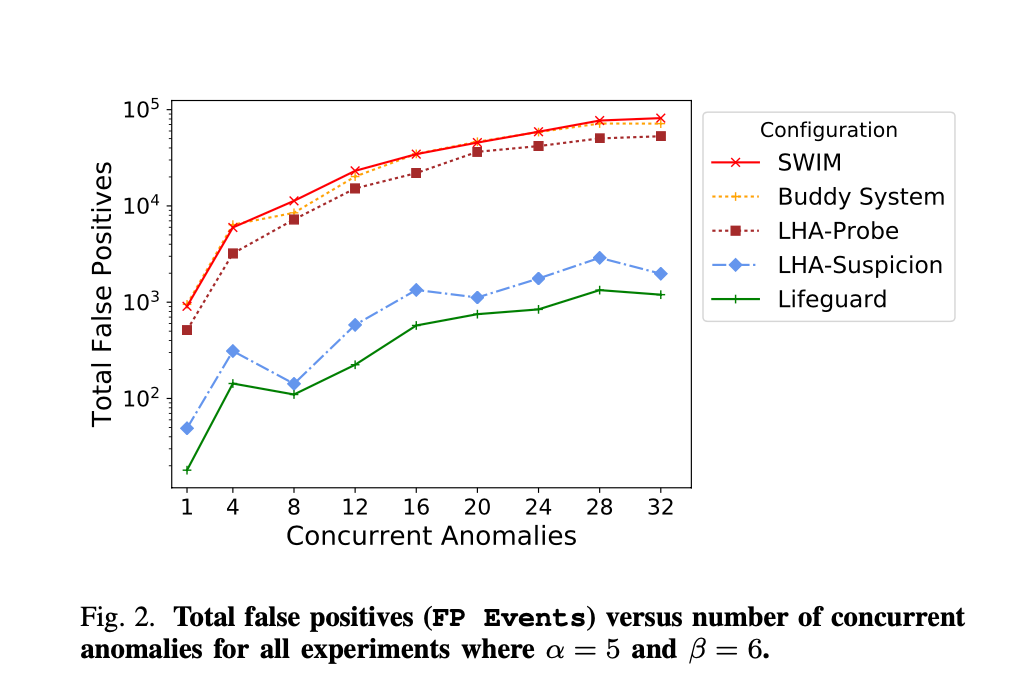
Benchmark

Hình vẽ trên cho thấy số message false-positive của failure detector trong từng thuật toán so với SWIM.
- FP Events: total false-positive failure message ở tất cả Consul agent.
- FP- Events: total false-positive failure message ở healthy Consul agent.
- FP % SWIM: percent of FP Events compare with base SWIM protocol
- FP- % SWIM: percent of FP- Events compare with base SWIM protocol
Message load benchmark
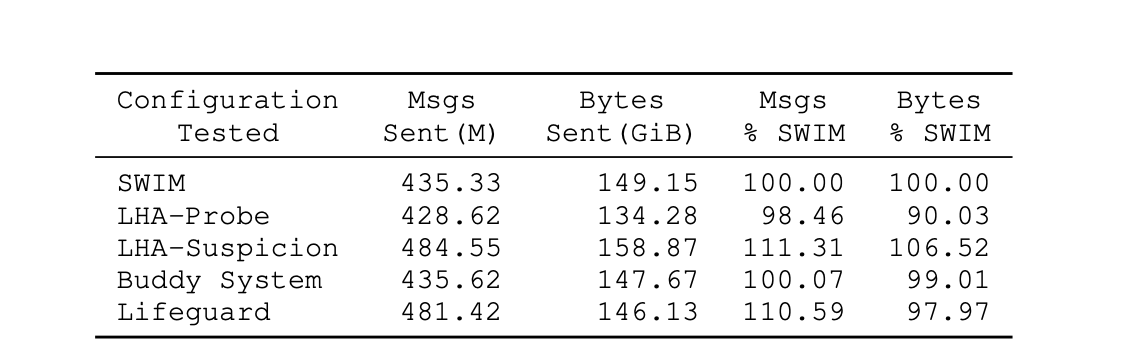
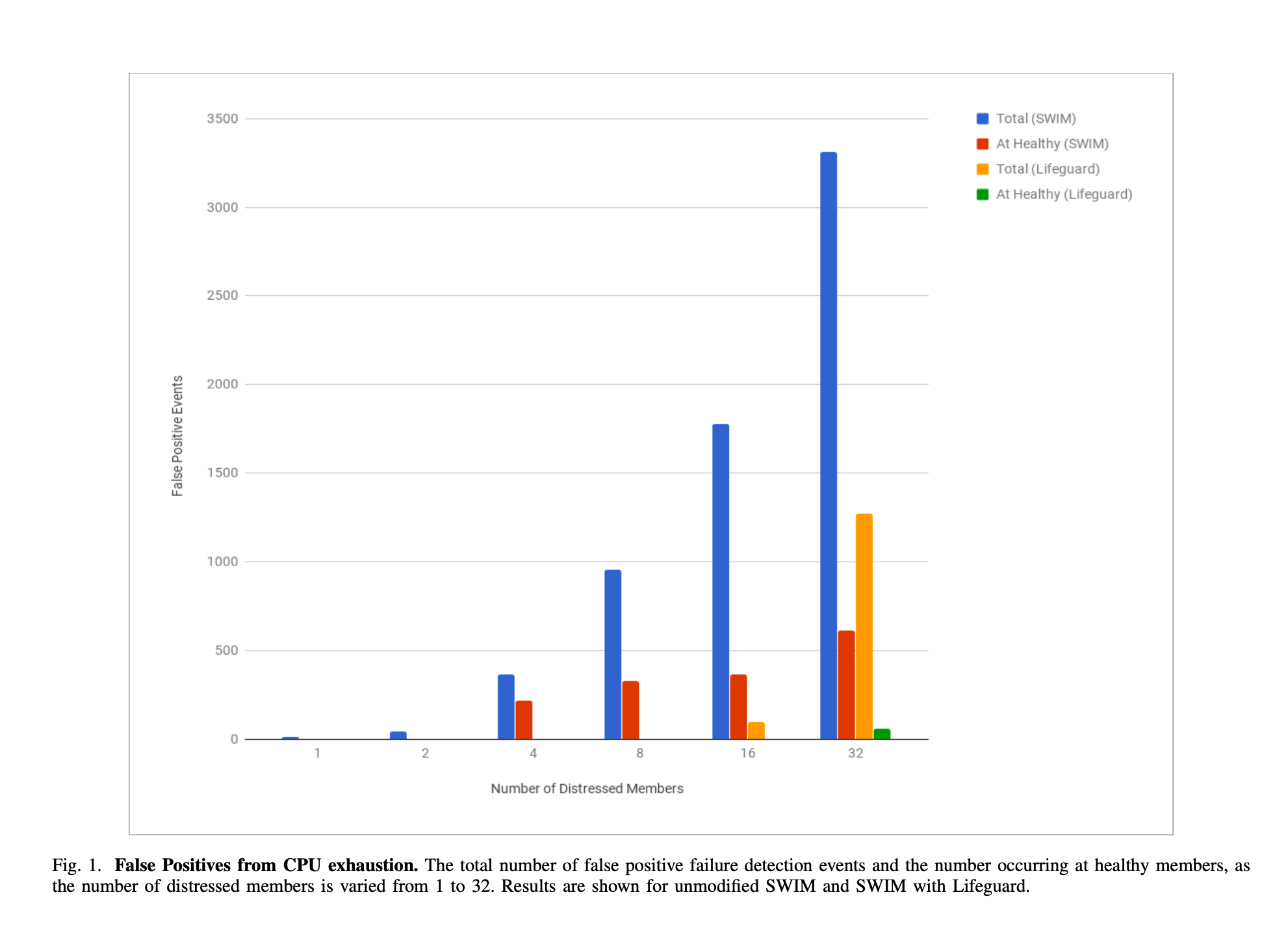

–> Default implementation: alpha=4 so that failures are now detected 20% faster with a 20x reduction in false positives
Bài học rút ra sau 2 paper SWIM và Lifeguard:
- Tư tưởng thuật toán khá rõ ràng và tường minh so với các paper khác từng đọc (e.g.: Raft). Khó: đưa ra một mô hình toán học và có thể chứng minh được upper bound và lower bound.
- Với paper SWIM: có nhiều kiến thức của foundation trong distributed system. thích hợp để đọc khi có một số các kiến thức liên quan.
- Cùng với Raft, đây là 2 paper được sử dụng trong thư viện hashicorp/membership, được sử dụng trong rất nhiều project “thân quen” như Consul; Nomad; … Hashicorp cũng làm rất tốt trong việc document các library này.