Nhận xét về paper Practical Byzantine Fault Tolerance: cách xây dựng hệ thống đồng thuận có thể chịu được lỗi Byzantine, đồng thời phải có khả năng chịu tải lớn. Đây là paper có ảnh hưởng lớn trong cộng đồng nghiên cứu về mô hình lỗi Byzantine.
Paper http://pmg.csail.mit.edu/papers/osdi99.pdf
Practical Byzantine Fault Tolerance
Ý tưởng xuyên suốt
- Tận dụng một thuật toán consensus sẵn có ở mô hình failure bình thường là ViewStamp Replication để giải quyết bài toán đồng thuận trong mô hình lỗi Byzantine.
- Xuyên suốt protocol, ta nhận ra một điểm quan trọng trong thiết kế: Chúng ta có thể tin tưởng một group, nhưng không thể tin tưởng bất kì một node đơn lẻ nào
Kiến thức cần biết
- standard consensus algorithms: Paxos / Raft / ViewStamp Replication / ZAB / …
- Fault tolerance
- Hiểu rõ một thuật toán đồng thuận bất kì.
Giới thiệu
Trong các bài toán về hệ thống phân tán, ta trước hết phải xây dựng có giả định về mạng / máy tính trước khi thật sự giải quyết. Các giả định thường đơn giản như:
- Một máy tính bị lỗi do bị ngừng hoạt động
- Bỏ sót một số tin nhắn
- Tạm thời ngưng hoạt động một thời gian sau đó hoạt động trở lại
Tuy nhiên, song song đó vẫn có một số lỗi ít tường minh và khó giải quyết hơn:
- máy tính có những hành vi tùy tiện không thể xác định được.
- Logic trên một node bị thay thế, từ đó không hoạt động đúng với thiết kế ban đầu. (malicious attack)
Qua đó, ta thấy Byzantine là mô hình lỗi abstract nhất. Tại sao các nhà khoa học máy tính lại rất quan tâm về vấn đê này?
- Cho dù tính đúng đắn của thuật toán đồng thuận chính xác, nhưng rất khó đảm bảo nền tảng thực thi (hệ điều hành / phần cứng) không bị lỗi, đẫn đến nội dung message bị thay đổi; delay; nuốt mất … Hay mở rộng ra, rất nhiều tình huống ta không thể ngờ trong thực tế. Hay mỗi khi ta nâng cấp hệ thống, cũng khó đảm bảo logic mới chạy hoàn toàn đúng với mong muốn (software bug)
- Nguy hiểm hơn, máy tính trong mạng bị thỏa hiệp từ bên thứ 3, từ đó dẫn đến các thao tác bất thường trong hệ thống. Yêu cầu này càng trở nên cấp thiết hơn, trong giai đoạn hiện tại khi mà mô hình blockchain nở rộ.
Do vậy, một thuật toán đồng thuận chịu được lỗi Byzantine là thuật toán mà không có bất cứ một giả định nào cho trước về các hành vi lỗi có thể gây ra bởi các node trong mạng, và do vậy toàn bộ hệ thống có thể vận hành bình thường hacker có thể nắm quyền trên một số các máy.
Đây là bài toán không dễ giải quyết. Với mô hình lỗi thông thường, để có khả năng chịu được f máy tính bị lỗi, hệ thống phải có tối thiểu 2f+1 máy tính. Đây cũng là tính chất phải có trong các thuật toán đồng thuận thông thường như Raft; Paxos; ZAB;
Trong mô hình lỗi Byzantine, để chịu được f máy tính bị lỗi, hệ thống phải có tối thiểu 3f+1 máy tính (một định lí đã được chứng minh). Song song đó, các thuật toán được phát triển trước đó đều có chi phí vận hành cao nên hầu như không khả thi trong thực tế.
Practical Byzantine Fault Tolerance được xuất bản năm 1999 là bài báo xử lí việc đồng thuận với mô hình lỗi Byzantine. Đây là bài báo đầu tiên có khả năng ứng dụng cao vì chi phí tương đối phù hợp trong lúc vận hành. Từ đó, bài báo này được sử dụng như nguồn tham khảo trong việc implement một blockchain như Tendermint; IBM’s Openchain; hay xây dựng một thuật toán chịu lỗi Byzantine khác.
ViewStamp Replication
Paper PBFT dựa rất nhiều vào thuật toán consensus ViewStamp replication. Do vậy, phần này ta có thể điểm qua một số điểm chính của thuật toán này. Ta có thể tham khảo kĩ hơn qua 2 paper sau:
- [Paper] Viewstamped Replication: A New Primary Copy Method to Support Highly-Available Distributed Systems
- [Paper] Viewstamped Replication Revisited
https://groups.google.com/g/raft-dev/c/cBNLTZT2q8o?pli=1
VR introduced some great ideas, and VRR was a huge improvement in clarity. I think the industry would be in a better place now with respect to consensus if it had paid less attention to Paxos and more to VR.
Raft author
Kiến trúc tổng quát
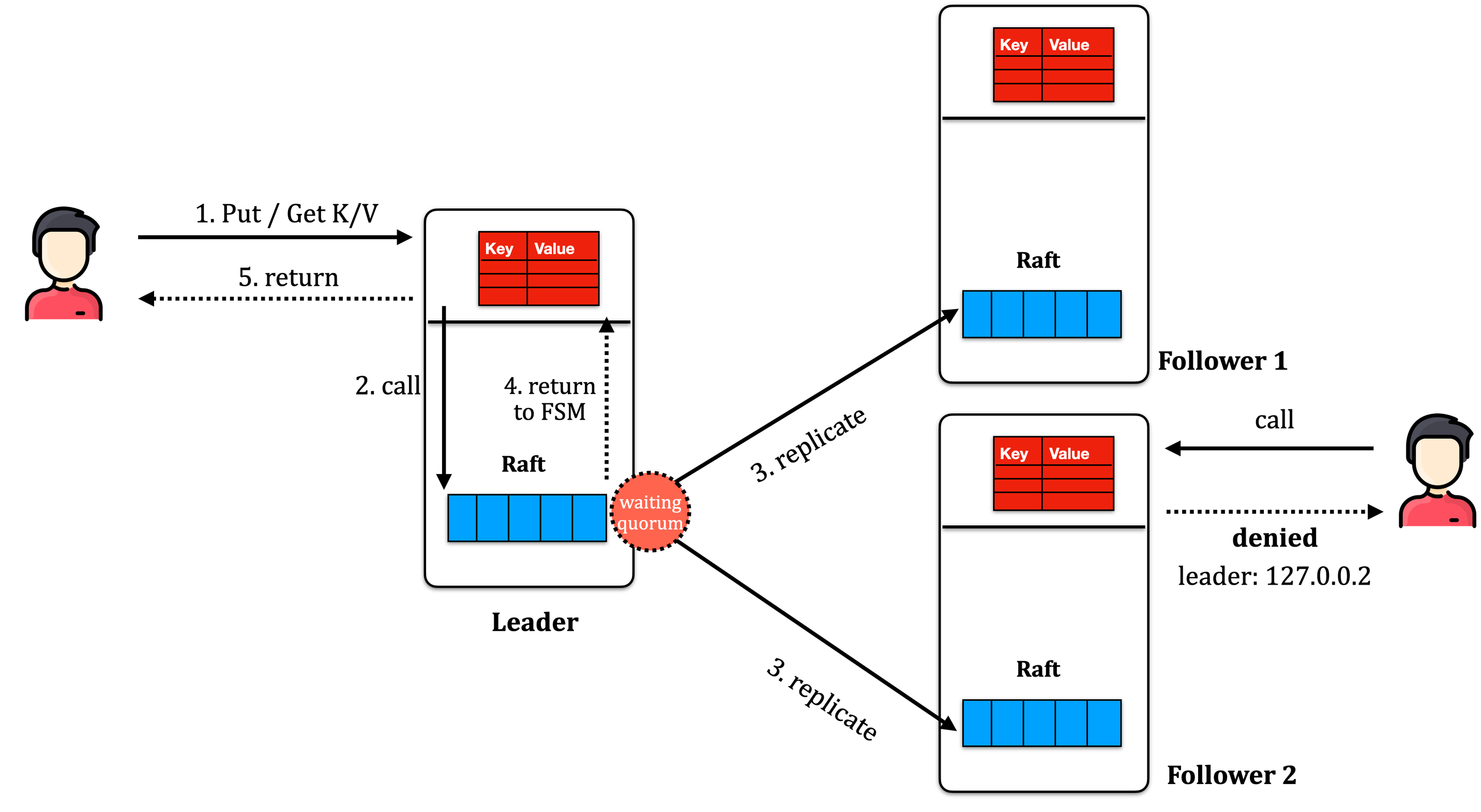
Các thuật ngữ
Cả ViewStamp replication và PBFT đều sử dụng 1 số các thuật ngữ sau.
- primary/leader: node trong mạng để điều phối toàn bộ các tác vụ
- view: Tương tự như term trong Raft, epoch trong ZAB và round trong Paxos. Khi mỗi leader được bầu chọn, leader sẽ run trong một view mới. Không bao giờ có 2 leader trên cùng một view.
- op-number: mỗi thao tác được ghi xuống log và id được đánh số tăng dần đều, ta gọi là op-number. Tương tự như index trong Raft và Paxos.
- commit number: khi môt log được commit, log đó sẽ được apply lên FSM; và trả về cho client. commit number của một node A là op-number mà tại vị trí đó, node A đã commit. Thông tin này rất quan trọng, vì một khi data được commit (và trả về cho client), data đó eventually buộc phải tồn tại trong mọi log của các replicas. Các thuật toán consensus luôn đảm bảo thứ tự commit các message là linearizable, hay nói cách khác, là duy nhất trên toàn bộ node.
- viewstamp: được format bởi [view].[op-number]. Các message được đánh viewstamp (một cách viết tắt để merge view và op-number vào một field). Do cách xây dựng → total ordering. viewstamp rất giống với zxid trong ZAB Protocol.
Normal Operation
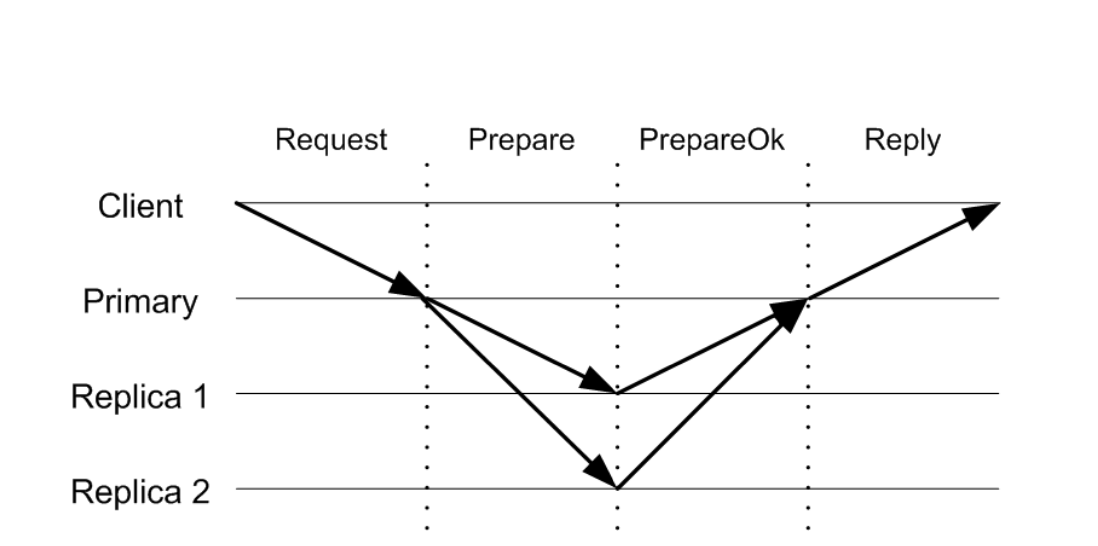
Step 1: Client gửi gói tin Request<op; c; s> tới node primary. Các param có ý nghĩa:
- op: operation (và bao gồm cả argument nếu có)
- c: client id
- s: request number được tạo ra cho request. Mục đích để cho request có khả năng idempotent. Server sẽ lưu một mapping clientID → RequestID → Response
Step 2: Primary nhận được request từ client
- compare request number và request number trong client table. Nếu request number <= mapping đó, drop request và trả về cache response.
- primary tăng ops-number lên 1 đơn vị. Append request vào log và update vào client table.
- Gửi
⟨PREPARE v, m, n, k⟩message to the other replicas. Các parameter có ý nghĩa:- v: current view number
- n: op-number được tạo cho request.
- k: commit number: commit number lớn nhất trên replica đó.
Step 3: Backup nhận được Prepare message
- Backup sẽ không nhận gói tin với op-number n nếu các op-number trước đó chưa nhận được → đảm bảo tính linearizable và đơn giản hoá mô hình
- Primary tăng ops-number lên 1 đơn vị. Append request vào log và update vào client table.
- Trả kết quả về cho primary
Step 4: Primary chờ ít nhất f response từ các backup.
Đến thời điểm này, sẽ coi thao tác này (đồng thời các thao tác trước đó là commited) → update FSM → trả về cho client gói tin ⟨REPLY v, s, x⟩
- v: view number
- s: request number lúc gửi lên
- x: result
Primary sẽ định kì gửi thông tin về Commit number cho các replicas để replicas có thể update lên FSM. Tương tự như các thuật toán consensus khác.
View Change
Step 1: Khi một node không nhận được heartbeat từ primary → trigger sự kiện ViewChange.
Step 2: node replica sẽ tăng view hiện tại lên 1. Leader tiếp theo sẽ là (view+1) % N
Step 3: node replica sẽ send request ChangeView tới node leader.
Nếu node leader nhận được quá bán số request ChangeView (bao gồm chính nó) → trở thành Primary ở view V+1.
Nhận xét với các thuật toán khác như Multi-Paxos/Raft: ở Multi-Paxos / Raft, khi timeout xảy ra → các node sẽ “tranh nhau” để trở thành leader tiếp theo (active election?). ở ViewStamp Replication thì ngược lại, leader ở view tiếp theo đã được “quyết định trước”
pBFT Thinking Design
Cryptography
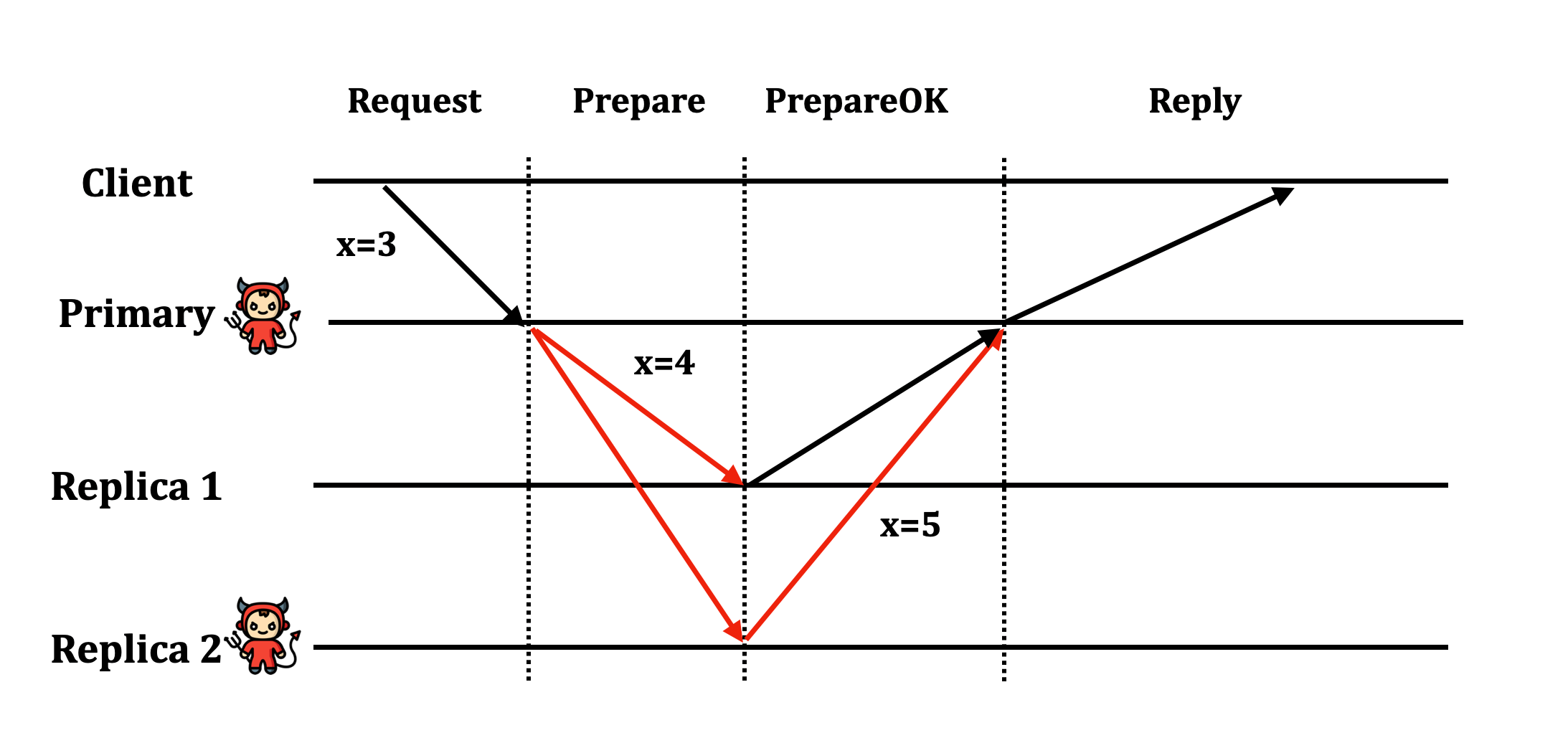
Ở mỗi step: Primary đến replica hoặc từ replica đến các node khác, các node đều có khả năng thay đổi nội dung tin nhắn. Do vậy, để đảm bảo tính toàn vẹn của dữ liệu, các tin nhắn đều dùng cơ chế public / private key encryption, và mặc định các node đều biết public key của nhau, và không node nào biết được private key của node khác.
Chọn số quorum
Vấn đề: Nếu primary là một fault node, primary có thể sửa đổi kết quả trả về.
Chúng ta có thể tin tưởng một group, nhưng không thể tin tưởng bất kì một node đơn lẻ nào
Nguyên lí này được áp dụng triệt để ở mọi bước của protocol.
Giải pháp: Thay vì để một node trả về kết quả, ta để cho group các node trả về kết quả và tuân theo quy luật số đông.
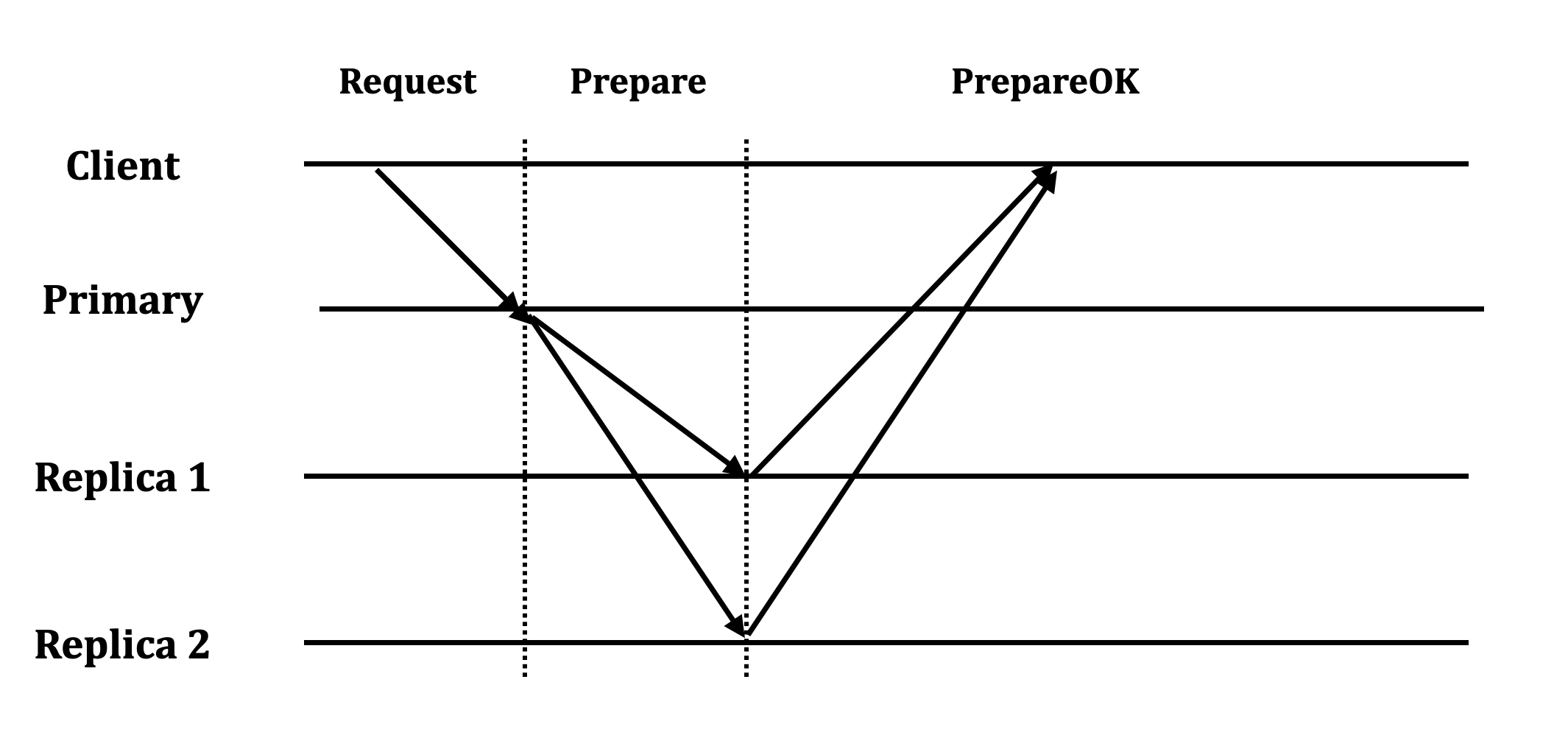
Câu hỏi: Với một hệ thống có f node failure, cần tối thiểu bao nhiêu kết quả trả về ?
Giải pháp 1: Traditional quorum
Với một traditional quorum như Paxos / Raft / ZAB. ViewStamp, để chịu được f failures ta cần tối thiểu 2f+1 node.
→ client sẽ chờ f+1 node từ 2f+1 node trong hệ thống. Đây cũng là số node tối đa client có thể chờ (vì f node lại có thể gặp lỗi thành ra không trả về kết quả)
Vấn đề:
- Không an toàn: Với f+1 kết quả, có thể có đến f node lỗi dẫn đến chỉ có 1 node còn lại chạy đúng. Như vậy, client không thể make decision được (ngoại trừ việc chắc chắn rằng xuất hiện lỗi trong hệ thống).
- Operation 2 cũng chờ cho f+1 node, và có thể correct node ở operation 2 không giao với correct node ở operation 1 → faulty primary có thể làm hệ thống chạy không chính xác.
Ví dụ: Với một hệ thống có 3 node S1 S2 S3. Một biến đếm là A có giá trị sẵn là 3.
- Client 1: gán giá trị A=4 và gửi tới S1
- S1 chỉ gửi request tới S2.
- S1 và S2 cùng trả về client với kết quả A = 4. Client 1 ghi nhận request success
- Client 2: đọc giá trị A và gửi tới S1
- S1 chỉ gửi request tới S3. S3 không nhận được request trước do vậy chỉ có ghi nhận A=3.
- S1 và S2 cùng trả về client với kết quả A = 3. Client 2 nhận giá trị cũ của A.
→ 2 quorum f+1 (over 2f+1) có thể không giao nhau bất kì một correct node nào.
Giải pháp 2: BFT Quorum
Một định lí đã được chứng minh: để một hệ thống chịu được tối thiểu f node byzantine fault tolerance, cần tối thiểu 3f+1 node trong mạng.
Giải pháp: client sẽ chờ 2f+1 node trong tổng cộng 3f+1 node trong mạng. Đây cũng là số node tối đa client có thể chờ, vì f node còn lại có thể là node lỗi, do vậy sẽ không bao giờ trả kết quả về.
Quay lại ví dụ trên, với một hệ thống có 4 node S1 S2 S3 S4. Một biến đếm A có sẵn gía trị là 3.
- Client 1: gán giá trị A=4 và gửi tới S1
- S1 chỉ gửi tới S2 và S3.
- S1 / S2 / S3 trả về cho client với kết quả A = 4. Client ghi nhận request success
- Client 2: đọc giá trị A và gửi tới S1
- S1 chỉ gửi tới S3 và S4.
- S1 / S3 / S4 lúc này trả về cho client, có thể là 2 kết quả: S1 và S4 là A = 3. Nhưng S3 sẽ trả về A = 4.
→ Client nhận được sự bất thường trong hệ thống. Sở dĩ ta có thể làm được, do bất kì 2 quorum 2f+1 (over 3f+1) giao nhau tại ít nhất một node hoạt động tốt.
Chứng minh phản chứng: giả sử tồn tại 2 quorum 2f+1(over 3f+1) mà không giao nhau tại bất kì một correct node nào.
- gọi Sx là tập node failure bất kì. Sx <= f (giả thiết) → -S >= -f
- quorum 1: (S1 + A). với S1 + A = 2f+1 → A = 2f+1 - S1 >= 2f+1 - f = f+1.
- quorum 2: S2 + B. tương tự, ta có: B >= f+1
- Size của toàn mạng >= S + A + B (do A và B giao nhau rỗng) = f + A +B >= f + (f+1) + (f+1) = 3f+2 (vô lí)
Pre-prepare request
Xét lại câu hỏi, một faulty primary có thể làm được gì ?
- gửi kết quả sai tới client
- Nuốt luôn request từ phía client
- gửi request khác nhau tới những replicas khác nhau
Giải pháp:
- Khắc phục bằng cách không để primary gửi trực tiếp kết quả về cho client.
- Client sẽ chú ý các thao tác. Nếu không thấy có progress sẽ thông báo với các replica các để thay đổi primary
- Cần có một bước verify lại information từ phía replicas. Nói cách khác, ngay bước Prepare, chúng ta đang tin tưởng hoàn toàn vào node primary → trái ngược với triết lí ban đầu: chỉ tin vào một group chứ không phải bất kì một node đơn lẻ nào.
Ta sẽ thêm vào một step là Pre-Prepare, sau đó, để đến được bước Prepare, các node phải nhận được ít nhất 2f+1 gói tin Pre-prepare từ các node (bao gồm chính nó) trong mạng.
Nói cách khác, pre-prepare request để đảm bảo ordering của message trong cùng một view.
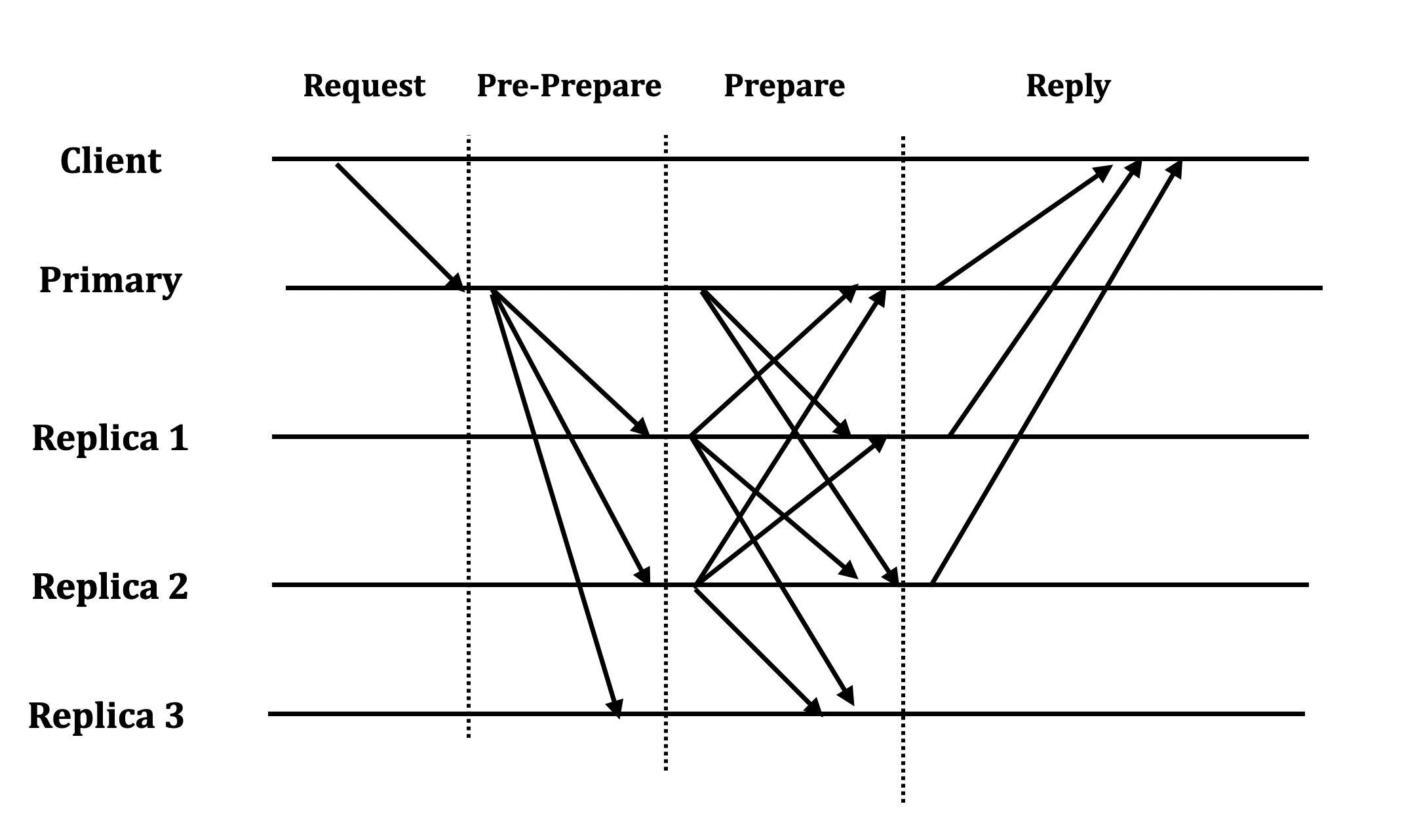
Commit request
Đặt tình huống khi có sự kiện ViewChange xảy ra, nhưng mới chỉ có một node nhận được toàn bộ các gói tin Prepare để đưa về trạng thái Prepared và commit.
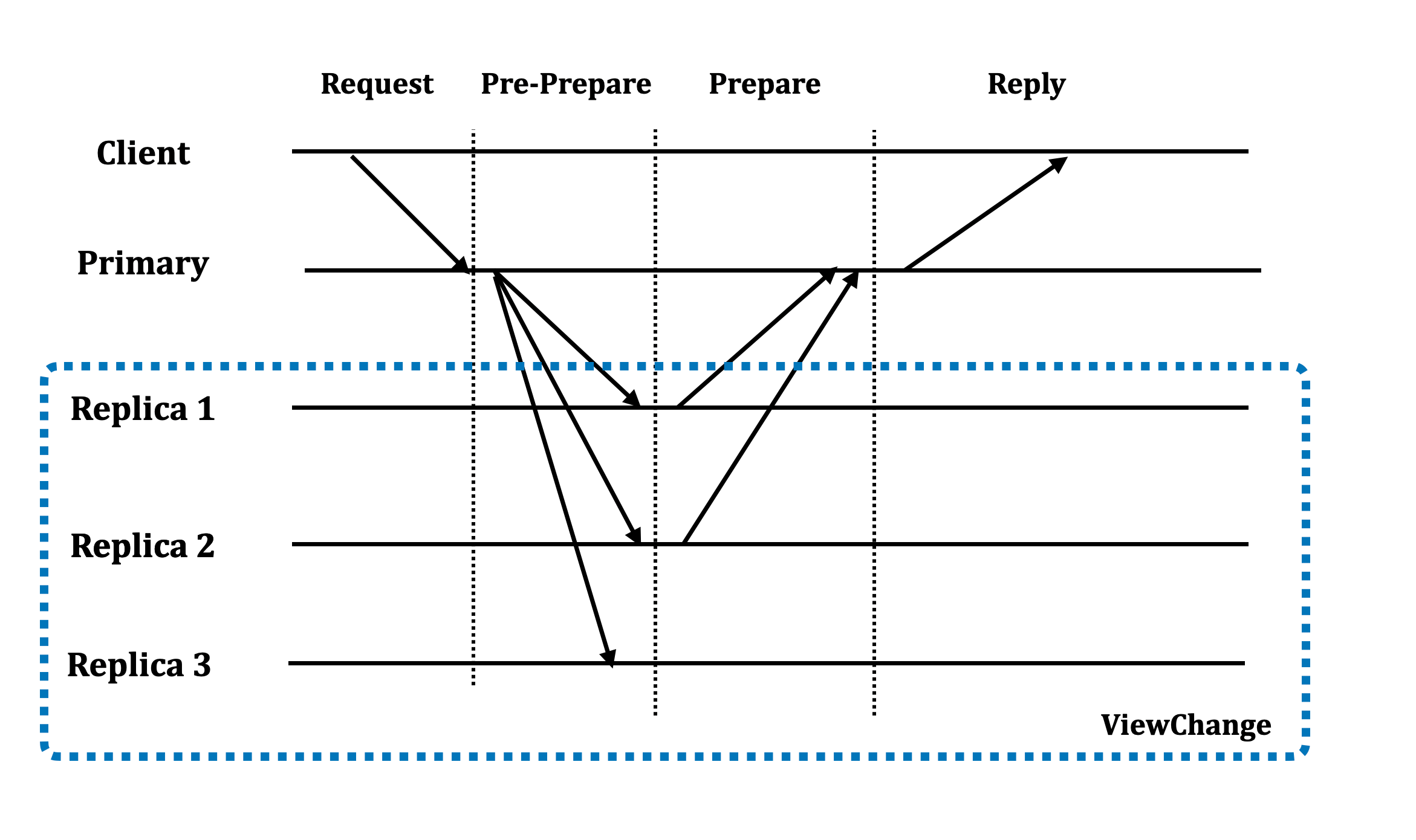
Qua hình vẽ trên, ta thấy một số điểm:
- Primary nhận được đủ số request Prepare và commit message
- Trước khi các node các kịp nhận được đủ gói tin Prepare (hoặc có thể là không nhận được do Primary cố ý không gửi), sự kiện ViewChange diễn ra.
- Giả sử việc bầu chọn chỉ diễn ra trong nội bộ 3 node: Replica 1 2 và 3. Ta thấy thông tin về message đã được commit ở view trước không thể biết được ở view hiện tại. Do vậy, thông tin về commited message sẽ bị lost ở view mới → là điều ta hoàn toàn không muốn.
- Ví dụ: commited message ở index là 20. Do message này không được bảo toàn qua view mới, do vậy ở view mới, một message mới cũng có thể được commit ở index là 20 → không đảm bảo tính lineariazability cho hệ thống.
Giải pháp: Ta thêm vào một phase Commit. Hay nói cách khác, Commit phase để đảm bảo các message được order đúng và duy nhất across view
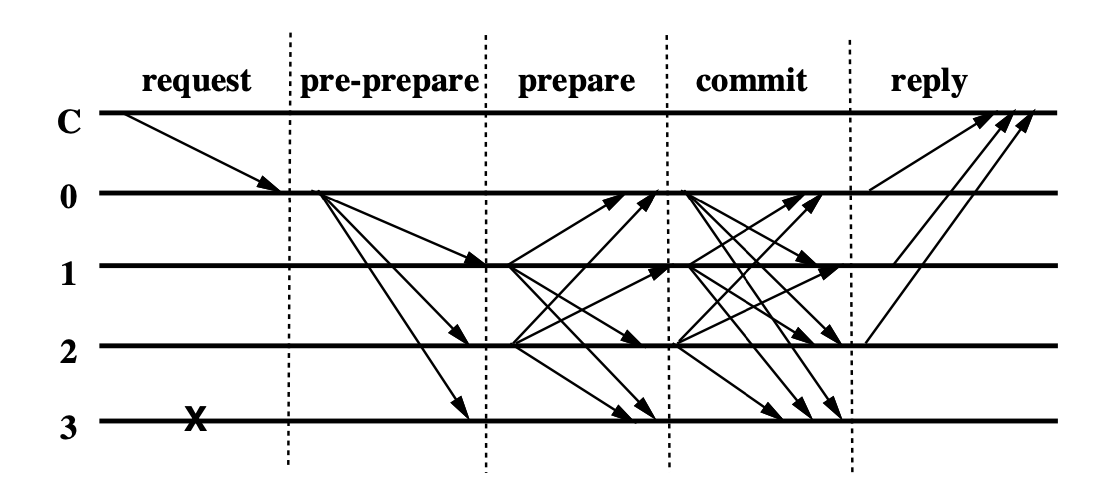
- Như vậy, sau khi nhận được tối thiểu 2f+1 gói tin
PREPARE→ chuyển qua trạng tháiPREPARED - Node sẽ gửi tiếp gói tin
COMMITra toàn mạng. Sau khi nhận được 2f+1 gói tinCOMMIT→ chuyển qua trạng tháiCOMMITED, đồng thời commit local và trả kết quả về cho client. - Client sẽ chờ cho f+1 commit message. Lưu ý: ta chỉ cần f+1 message trong trường hợp này, vì trong f+1 commit message, có ít nhất 1 node là correct node. Để correct node này trả về được 1 commit message, ít nhất node này đã nhận được F+1 gói tin commit từ các correct node → F+1 gói tin
PREPAREtừ các correct node.
ViewChange Protocol
Tương tự như thuật toán ViewStamp Replication, khi một node nhận thấy timeout từ Primary, sẽ tăng view lên 1, và gửi message DoViewChange đến leader của view này (view+1 % N)
New primary sau khi nhận đủ 2f+1 View Change request (bao gồm chính nó) → Gửi message New-View ra toàn mạng
Câu hỏi: Với design này, new primary có luôn thấy được toàn bộ message đã được commit ở view trước?
Trả lời:
- Replica chỉ commit khi có ít nhất 2f+1 node đã commit message
- new primary chờ
View Changestừ 2f+1 replicas. Như ta đã trình bày, 2 quorum (2f+1) phải giao ít nhất một good node, mà node này đã gửi commit message. - Một node chỉ gửi commit message khi nhận được đủ 2f+1
PREPAREmessage, trong đó ít nhất là từ f+1 good node. - Do vậy, chắc chắn các message đã được commit ở view trước sẽ được gửi cho view tiếp theo.
PREPARE certificate
Vấn đề
Xét trường hợp một mạng có:
- f fault nodes: một primary và (f-1) replicas
- A: f+1 correct node
- B: f correct node
Gọi message (m, n) với m là message từ phía client và n viewstamp của message. Khi một client gửi request tới fault primary, primary sẽ tạo ra một kịch bản:
- (m, n) tới A
- (m’, n) tới B
- f fault nodes: khi nói chuyện với A sẽ dùng (m, n) và khi nói chuyện với B sẽ dùng (m’; n)
Nói cách khác, primary tạo ra 2 tập good replica: mỗi tập replicas nhận được message khác nhau tại cùng một viewstamp. Theo thuộc tính quorum, (m, n) sẽ được commit vì tổng cộng số message (m, n) được ghi nhận là f + A = 2f+1.
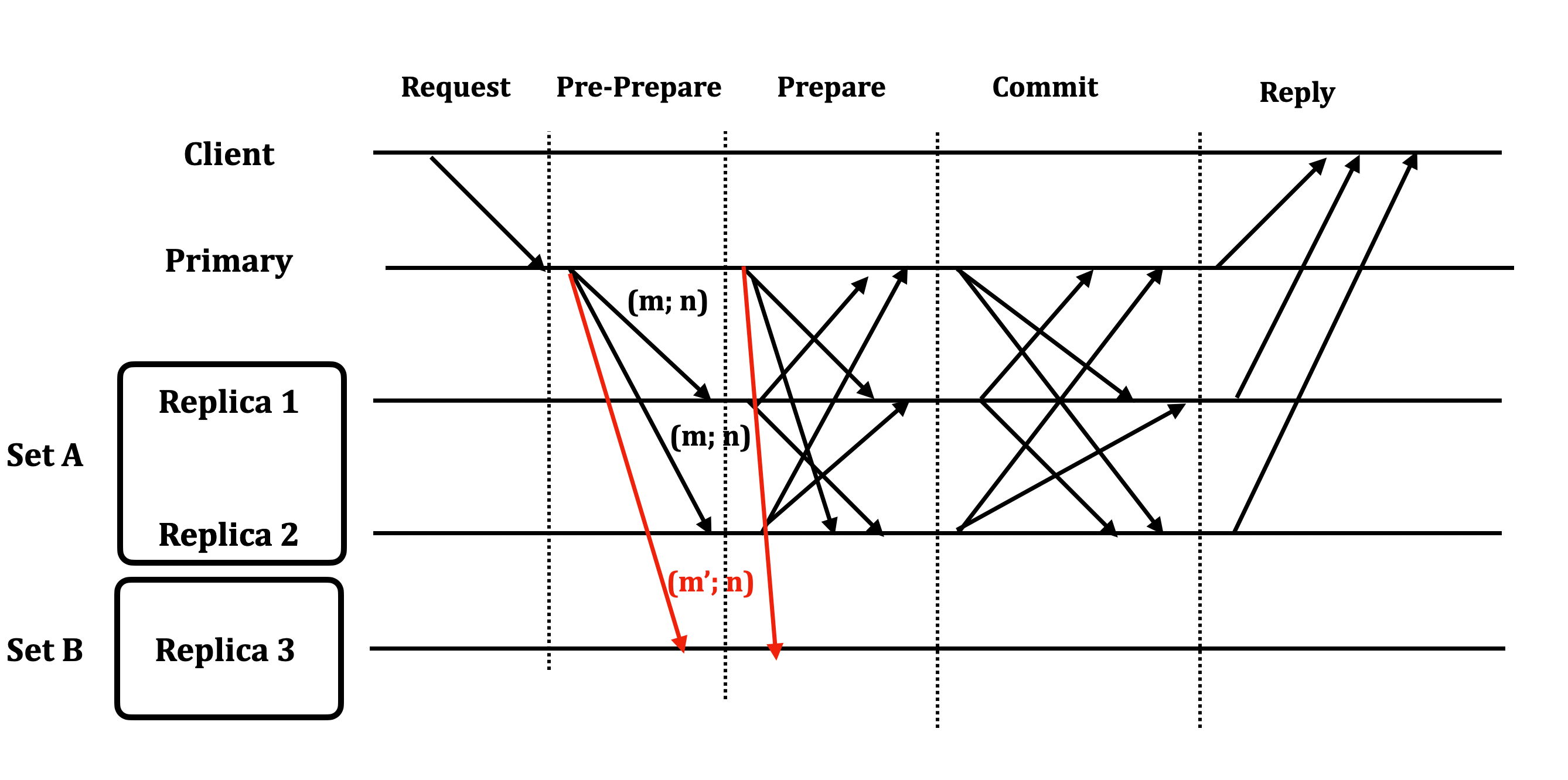
Tuy nhiên, giả sử khi sự kiện ViewChange diễn ra và chỉ có một node của A tham gia vào event (đây là con số tối thiểu cần có như đã chứng minh phần trên qua việc thêm một step COMMIT)
Ví dụ với trường hợp trên thì chỉ có Primary + Replica 1 + Replica 3 tham gia vào ViewChange và leader của view này là Replica 3. Với viewpoint của replica 3 khi nhìn vào index tại N:
- replica 3: (m’; n)
- primary: (m’; n)
- replica 1: (m; n)
Ta thấy trong tình huống này, (m; n) chỉ chiếm thiểu số trong ViewChange (dù đúng) . Do vậy, hệ thống không thể giải quyết được conflict (hoặc có thể giải quyết sai).
Từ đó, ta có một nhận xét là: Ý kiến số đông không thể giải quyết triệt để khi chuyển view. Lí do: có thể chỉ có 1 correct node chạy ở view trước tham gia vào quá trình ViewChange của view tiếp theo.
Giải pháp
Dùng certificate: là tập hợp của các signed message từ 2f+1 replicas. Mục đích của certificate để chứng thực một sự kiện đã xảy ra trong quá khứ. Certificate được sign bởi private key của các node nên không thể nguỵ tạo được.
P-certificate tại ith: Prepare-certificate. tập hợp các signed prepare message từ 2f+1 replicas cho index ith.
Với hình vẽ trên: Khi bầu chọn leader mới, các node sẽ lần lượt gửi message tới primary của view tiếp theo (Replica 3 trong trường hợp này) list các Prepare Message nhận được trên chính node đó.
- Primary: có 2 cách để gửi
PrepareMessage(Primary->Primary; M'; N)PrepareMessage(Replica 1->Primary; M; N)+PrepareMessage(Replica 2->Primary; M; N)
- Replica 1:
PrepareMessage(Primary → Replica 1; M; N)+PrepareMessage(Replica 2 → Replica 1; M; N)+ Chính nó - Replica 3:
PrepareMessage(Primary -> Replica 3; M'; N)
Trong cả 2 trường hợp gửi của Primary, Replica 3 khi nhìn vào lịch sử sẽ thấy chỉ có danh sách từ Replica 1 là hợp lệ (đủ 2f+1 node) và do đó, sẽ chọn chọn message (M, N)
Question: Thay vì dùng P-certificate, ta thay bằng C-certificate được không?
Answer: Không thể. Vì như đã discuss ở phần trước, có thể node đã commit message không tham gia vào sự kiện bầu chọn ở view mới.
Practical Byzantine Fault Tolerance (PBFT)
Dựa trên những kết quả đạt được ở phần trên, ta có thể bắt đầu cụ thể hóa thuật toán
Quy ước ban đầu
Ta kí hiệu message M được sign bởi tác nhân i là: Sign_i<>
Các node sẽ giao tiếp với nhau thông qua public encryption. Do vậy, các node sẽ có public key của các node khác trong mạng.
Normal Operation
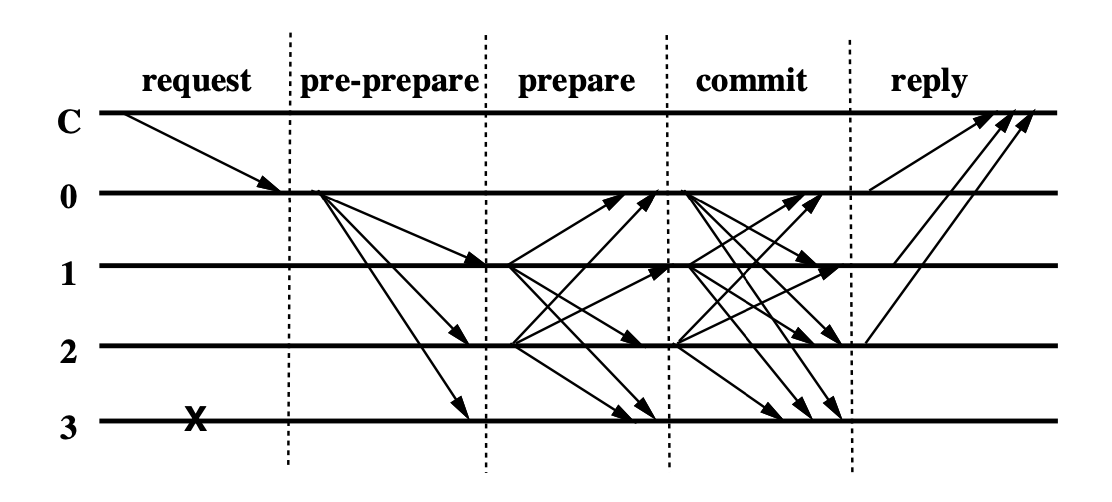
Step 1: Client C gửi request O tới primary 0 với message Sign_C<Request; o; t; c>
- o: operation
- c: client id
- t: timestamp. Để đảm bảo exactly once, server sẽ lưu lại mapping giữa
client id → <timestamp; response>và sẽ trả về kết quả lập tức khi một message đã được thực thi.
Step 2: Primary sẽ gửi message <Sign_Primary<PRE-PREPARE; v; n; d>; m>
- v: view hiện tại
- n: sequence number tăng dần đều.
- d: m’s digest để verify tính toàn vẹn của dữ liệu
Step 3: Backup sẽ nhận gói tin PRE-PREPARE từ primary và kiểm tra
- signature của request và pre-prepare message là khớp
- d là digest của m (chứng tỏ m không có chỉnh sửa)
- n nằm trong đoạn cho phép [h; H]
Nếu đồng ý, backup sẽ lưu gói tin này xuống log, đồng thời broadcast gói tin Prepare toàn mạng Sign_BackUp_i<PREPARE, v, n, d, i> với i là node id gửi đi.
Step 4: Các replicas khi nhận được gói tin PREPARE
- view number của mesage khớp với view hiện tại
- n nằm trong đoạn cho phép [h; H]
Nếu đồng ý, replica sẽ lưu gói tin này xuống log, và chờ nhận được 2f gói tin PREPARE khác trong mạng. Khi đó, hệ thống đã ghi nhận 2f+1 gói tin PREPARE. Khi đó, node sẽ broadcast gói tin COMMIT ra toàn mạng. Gói tin COMMIT có format như sau Sign_Replica_i<COMMIT; v; n; D(m); i>
Step 5: Các replicas khi nhận được gói tin COMMIT, sẽ kiểm tra
- nếu view của message trùng khớp với view hiện tại
- n nằm trong đoạn cho phép [h; H]
Nếu đồng ý, replica sẽ ghi gói tin COMMIT xuống log.
Step 6: Các replicas khi nhận được 2f+1 gói tin COMMIT
Trả kết quả về cho client với message Sign_Replica_i<REPLY; v; t; c; i; r>
- r: kết quả trả về
- v: view hiện tại của replica
- t: timestamp của request lúc client gửi đi
- c: client id
Step 7: Client chờ kết quả
Client sẽ chờ cho f+1 kết quả từ phía server. Kiểm tra nếu cùng t và r → accept kết quả.
Nếu client không thể nhận được kết quả trong thời gian cho phép, client sẽ broadcast request ra toàn bộ các replica trong mạng.
- Primary: Nếu request đã xử lí, trả lại kết quả đã lưu mà không cần thực thi.
- Backup: gửi request lên primary. Nếu sau đó không nhận được reply từ Primary → nghi ngờ primary bị lỗi và khởi tạo quá trình
VIEWCHANGE.
View Change Algorithm
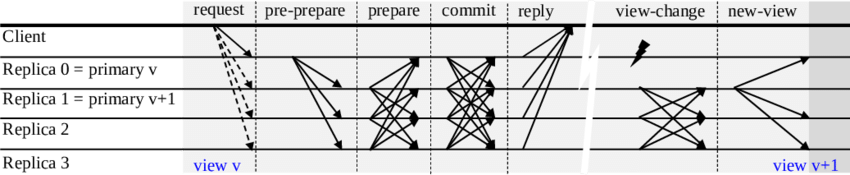
Thuật toán:
Step 1: Tương tự như thuật toán ViewStamp Replication, khi một node nhận thấy timeout từ Primary, sẽ tăng view lên 1, và gửi message DoViewChange đến leader của view này (view+1 % N). Format của message là Sign_Replica_i<DoViewChange v; P; i>
- v: view của replica tại thời điểm gửi
- i: node id
- P: tập hợp của các Prepare-certificates mà i biết được (tập hợp này sẽ rất lớn, và sẽ được giải quyết bằng cơ chế Checkpoint)
Step 2: New primary sau khi nhận đủ 2f+1 DoViewChange request (bao gồm chính nó)
- Xây dựng lại log dựa trên toàn bộ prepare certificate (có thể tối ưu dựa vào cơ chế checkpoint)
- Chuyển status về normal và gửi
Sign_Primary_P<StartView mlist; v; O>đến toàn bộ các replica khác trong mạng- mlist: list của toàn bộ
DoViewChangemessage nhận được để chứng thực việc chuyển view này là hợp lệ. - O: tập hợp của
Sign_Primary_P<Prepare d; v; n>
- mlist: list của toàn bộ
Step 3: Replica khi nhận được sự kiện StartView từ new replica:
Chạy lại toàn bộ các thao tác trong tập hợp O (chỉ bắt đầu từ các message chưa được khởi tạo). Điều này quan trọng vì các replica phải build được toàn bộ thông tin từ đầu đến hiện tại, không chỉ thông tin về log từ client mà cả các message trong mạng nội bộ → để có thể bắt đầu verify lại tương tự cho lần ViewChange tiếp theo.
Bài toán khác
- Checkpoint
- Cryptography: Sử dụng MAC thay cho public-private key scheme.
Nhận xét
- Đây là một paper hay và khó, tuy nhiên, lại phụ thuộc nhiều paper và context trước đó.
- Có được góc nhìn về cách xử lí đồng thuận trong mô hình byzantine thế nào: không bao giờ tin vào một cá nhân, mà thay vào đó tin vào group. Với một số trường hợp chỉ có decision từ một phía, cần có proof (certificate) để chứng thực các sự kiện xảy ra trong quá khứ.
- Có các bước phát triển khá tự nhiên từ một thuật toán consensus có sẵn.
- Gộp chung 2 lỗi node failure và network failure vào làm một. Một số protocol khác dựa trên paper này có thể tách ra thành 2 loại lỗi khác nhau → tối ưu hoá hơn cho hệ thống.
- Paper này có ảnh hưởng lớn trong cộng đồng nghiên cứu về byzantine fault tolerance consensus.
Các liên kết khác
From Viewstamped Replication to Byzantine Fault Tolerance
Paper: Viewstamped Replication Revisited
https://cs.stackexchange.com/questions/54152/why-is-the-commit-phase-in-pbft-necessary
https://ug93tad.github.io/pbft/
https://blog.brunobonacci.com/2018/07/15/viewstamped-replication-explained/